Case Study
1. Introduction
One of the main challenges for event-driven microservices architecture is how the system handles the volume and velocity of data that needs to be distributed to different services. Many services may rely on the same event data but require it in different formats. One solution, event-stream processing, involves processing and transforming events as they arrive in the system before distributing them to their respective services. Event-stream processing decouples data writes from data reads. This means the ability to choose the ideal tools and formats for both reads and writes. Event-stream processing is a powerful solution for delivering event data in real time by centralizing event transformations in a single pipeline.
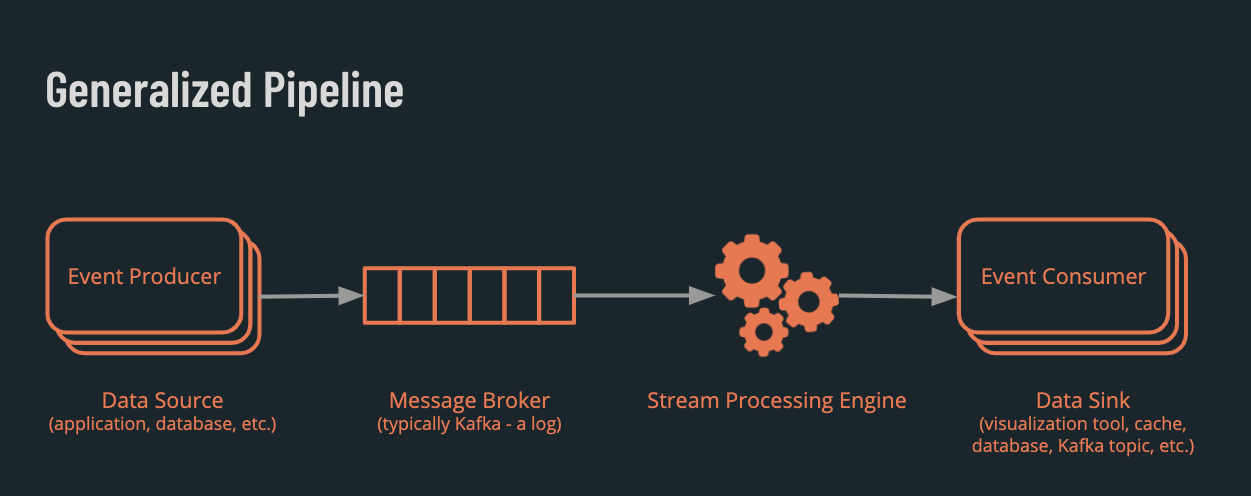
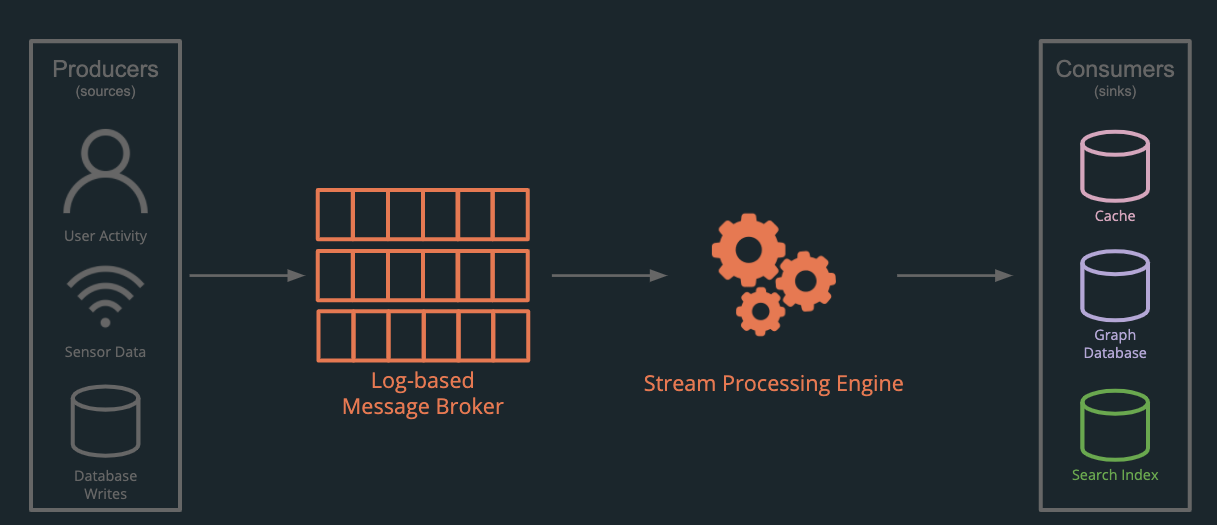
The implementation of these pipelines differs greatly, but essentially they have several components that are connected to achieve the following workflow:
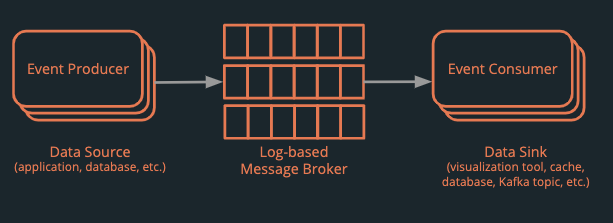
- Event producers generate event messages
- The events are transmitted from the producer to the message broker
- From the broker, they are consumed by the stream-processing engine for transformation
- Event consumers read the transformed event data
Developing and deploying an event-stream processing pipeline is typically expensive, complex, or both. Venice is an open-source framework that enables small teams starting out with event-stream processing to quickly deploy and manage an event-stream processing pipeline.
Venice is built for smaller applications and for developers with limited event-streaming knowledge. It uses open source components to set up a stream processing pipeline with reasonable default settings and simple management tools within minutes.
Developers building their first event-stream processing applications face some key challenges:
- Choosing between a number of potential components and creating a functioning pipeline.
- Connecting services to the pipeline to read the processed data.
- Ensuring consistency and correctness of data at all stages of the pipeline.
- Persisting event data and transformed data to populate materialized views and add new sinks as requirements change.
Venice abstracts away much of this complexity so that developers can focus on application code, rather than building and future-proofing this pipeline. Venice is a fully extensible foundation from which small streaming applications can grow as requirements shift.
This case study outlines the design, architecture, and implementation challenges of Venice. The value of Venice may become more apparent with insight into some of the problems that events and event-stream processing solve for distributed web applications.
2. Background
Many applications start out as simple monoliths. Over time, as requirements grow and become more complex, the need for scale prompts many to shift to a service-oriented architecture, such as microservices [1, Ch. 1].
One of the goals of microservices is to decouple services from each other. However, multiple services often require access to the same underlying data, including historical data.
How might an organization propagate data to multiple services in real-time without sacrificing availability1 or consistency, while retaining the flexibility to use historical data?
1Availability here means the opposite of downtime. If a system is responsive it is available.
2.1 It is difficult to share data between distributed services
An application might resemble this: a jumble of requests and data propagations between the application, a primary database, data warehouse, business analytics engine, search index, cache, and graph database.
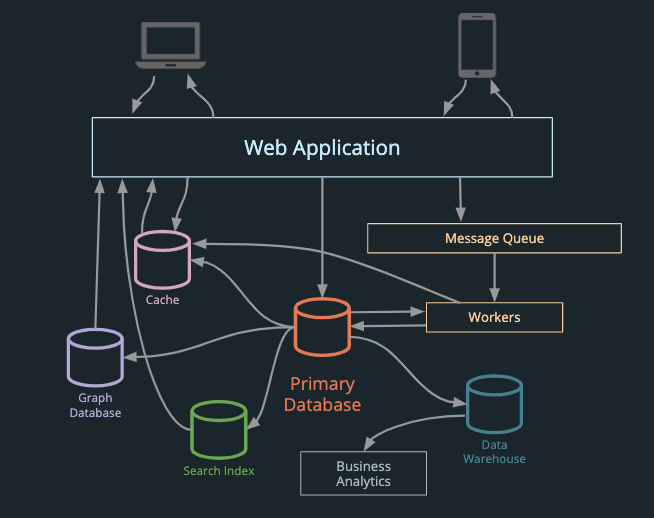
1 Figure inspired by [2, Ch 2].
There are numerous ways to use data from this application, and different tools are better suited for different situations. For example, an e-commerce application might use orders data to continuously update:
- A cache of “deals of the day” and remaining inventory, to avoid overloading the database with redundant queries.
- A search index, to enable full-text search of available products.
- A key-value store of personalised product recommendations for customers.
These outputs are all derived views of the same underlying data. Typically, it is difficult to maintain real-time services – such as the stock inventory, search index, or product recommendation services from above – without sacrificing the availability of the services or consistency of data. When a product runs out of stock, this change would ideally be propagated instantly to all these services, instead of hourly or daily. From a user and business perspective, it is desirable to update the shop as close to real time as possible. This would prevent displaying out-of-stock products to users.
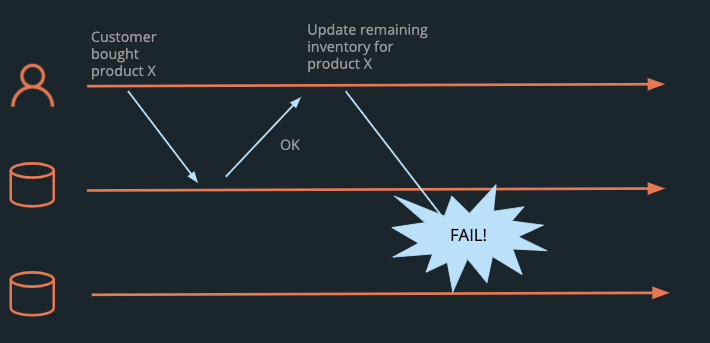
Dual writes are one way to update data across multiple services. However, partial failures, such as a network outage, can result in permanent inconsistency. Imagine writing orders to one database and updating remaining inventory in a different database. If a new order comes in for Product X, and is written successfully to the orders database, but the network crashes before the remaining inventory is updated, the two data stores are now inconsistent, and will remain that way without a manual recount.
Distributed transactions can provide consistency, but may sacrifice availability, because partial failures can render the application extremely slow or unresponsive [2, Ch. 2; 3].
To address this challenge, some companies have turned to using events to propagate data changes between their services.
2.2 Events drive application behavior
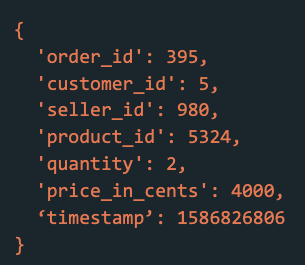
An event is an immutable object that describes something that happened at some point in time in an application [4, Ch. 11]. For example, if a new order is placed, that order can be modeled as an event as follows:
An event can trigger one or more actions. For example, when a new order comes in, the event can trigger an update to the inventory, start the fulfillment process, and send an email notification to the customer.
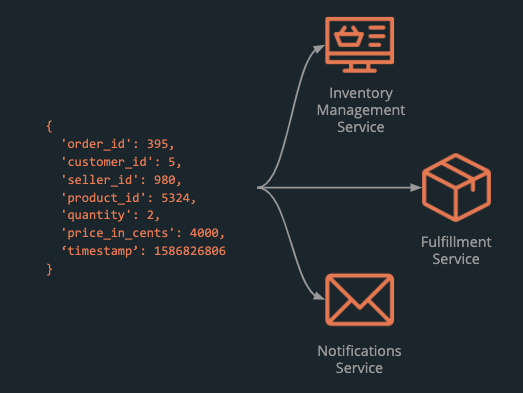
In streaming terminology, a producer generates an event. Related events are grouped together into a stream (also known as a topic). That event is then processed by one or many consumers [4, Ch. 11]. In the example above, the application is the producer. When a customer creates a new order, the application produces an event to the orders stream. The inventory management, fulfillment and notifications services are the consumers who receive the event and take appropriate action.
2.3 Message brokers move data from producers to consumers
Message brokers are suited for situations where:
- producers and consumers are asynchronous.
- multiple producers may write to a topic, and multiple consumers may read from a topic.
There are two common types of message brokers: (1) message queues (brokers that implement the AMQP and JMS standards) and (2) log-based message brokers.
2.3.1 Message queues do not retain events and may process events out of order

Message queues (e.g., RabbitMQ, ActiveMQ) are preferable in situations where:
- each event may take a long time to process.
- processing order is not important.
- event retention is not required.
Recall that the motivating question was: How might an organization propagate data to multiple services in real-time without sacrificing availability or consistency, while retaining the flexibility to use historical data?
Message queues are not the answer because they may process events out of order and do not retain events [4, Ch. 11].
2.3.2 Log-based message brokers retain events and help guarantee order
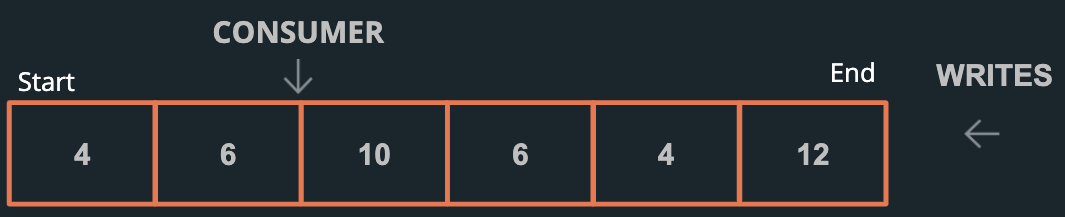
Log-based message brokers (e.g., Apache Kafka, Amazon Kinesis Streams) are preferable in situations where:
- each event can be processed quickly.
- processing order is important.
- event retention is required [2, Ch. 2; 4, Ch. 11].
Log-based message brokers are the answer to the motivating question.
-
Data can be propagated to services in real-time.
- Low Latency: Each write is an append operation, and a read is a linear scan. Producers can write data to the log in a single step, and consumers can read data from the log very quickly.
- High Throughput: Logs can be split into partitions and replicated across machines. This means many reads and writes can proceed concurrently [5].
-
The system is fault-tolerant.
- With multiple brokers, messages are rerouted to replicas if one crashes.
- With partitioned data and load-balanced consumers, if one consumer fails, others can pick up the work.
-
Data is consistent across services.
- Events are ordered within partitions. Keyed partitions route events with the same key to the same partition, ensuring order. For example, partitioning by product ID allows all orders for Product X to be processed in the order they are produced.
- Logs are immutable. Services that require the same underlying data will all see the same data. This avoids inconsistencies due to race conditions associated with having multiple databases.
-
Historical data is preserved.
- Logs contain historical information and new information. New services can be added to the system at any time, consume the historical data, and follow future events automatically.
- Developing new services is also possible, with the option to gradually transition, or roll back changes.
2.3.3 A note on the limitations of logs
Log-based approaches are not the answer to all problems. Events are consumed in a linear fashion, so a single event taking a long time to process could delay processing of later events. [4, Ch. 11]. Ordering of events is only guaranteed within an individual partition, which may be problematic as the system scales. The system also does not support reading self writes [4, Ch. 5], and other linearizability guarantees [4, Ch.9, Ch. 12]. In many cases, the benefits outweigh the drawbacks, and log-based message brokers present a powerful solution to the problem of propagating data to multiple services in real-time, without sacrificing availability and consistency, while retaining the flexibility to use historical data.
2.4 Stream processors abstract common operations out to a fast and fault-tolerant engine
It is common to have multiple services use the same data to generate different outputs in an application. The outputs generated may be different, but many of the operations used by the services to process these events are the same. These operations include windowing, aggregation, joins, filters, and transformations [6].
Individual consumers can be written to perform these operations. This works well for operations such as filtering or transforming that process one message at a time. This approach becomes more challenging when operations are more complex, for example, aggregating over time or joining two different streams together.
Event stream processors abstract these common processing operations to an engine. Such an engine can provide additional benefits such as fault tolerance, efficient processing of events via clusters, maintenance of local state, and out-of-order events handling [7].
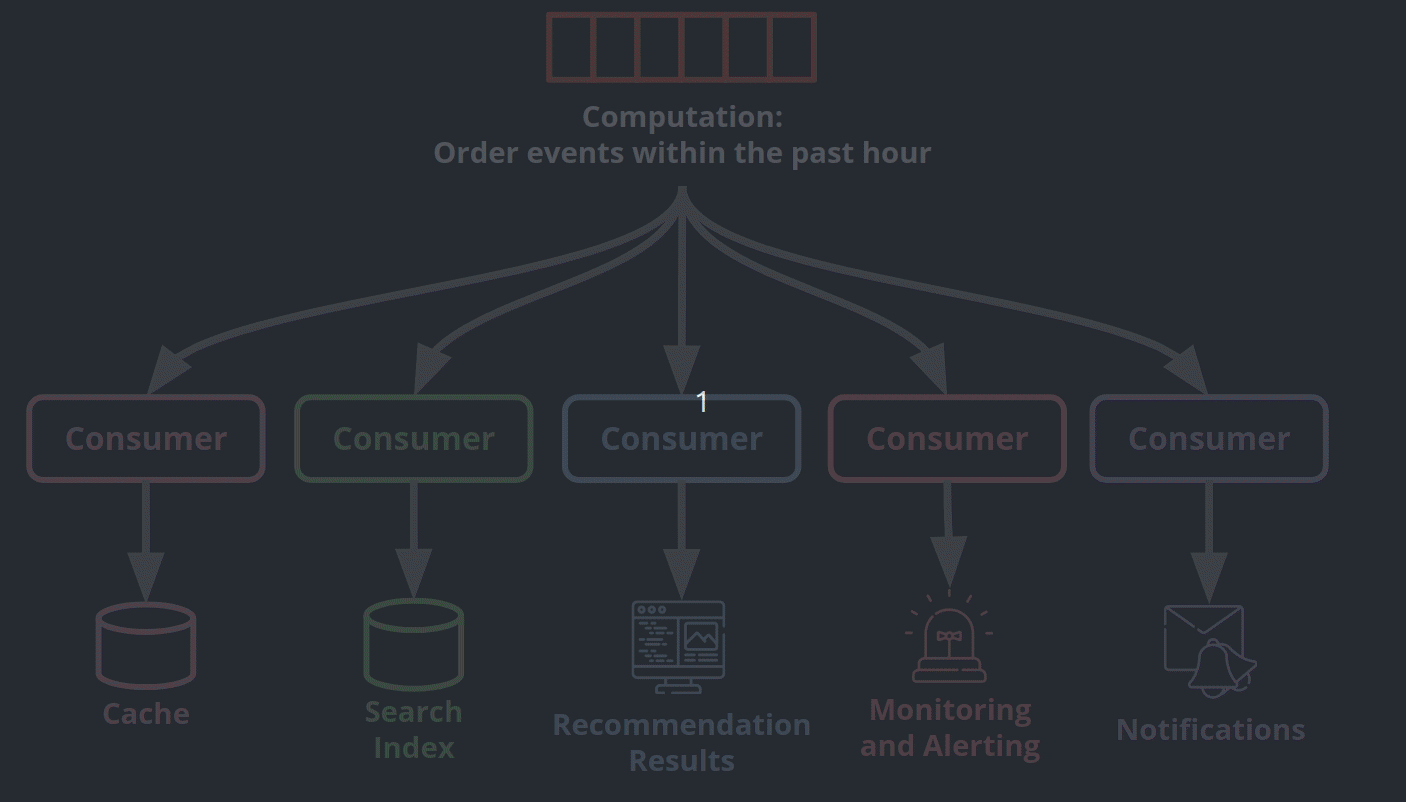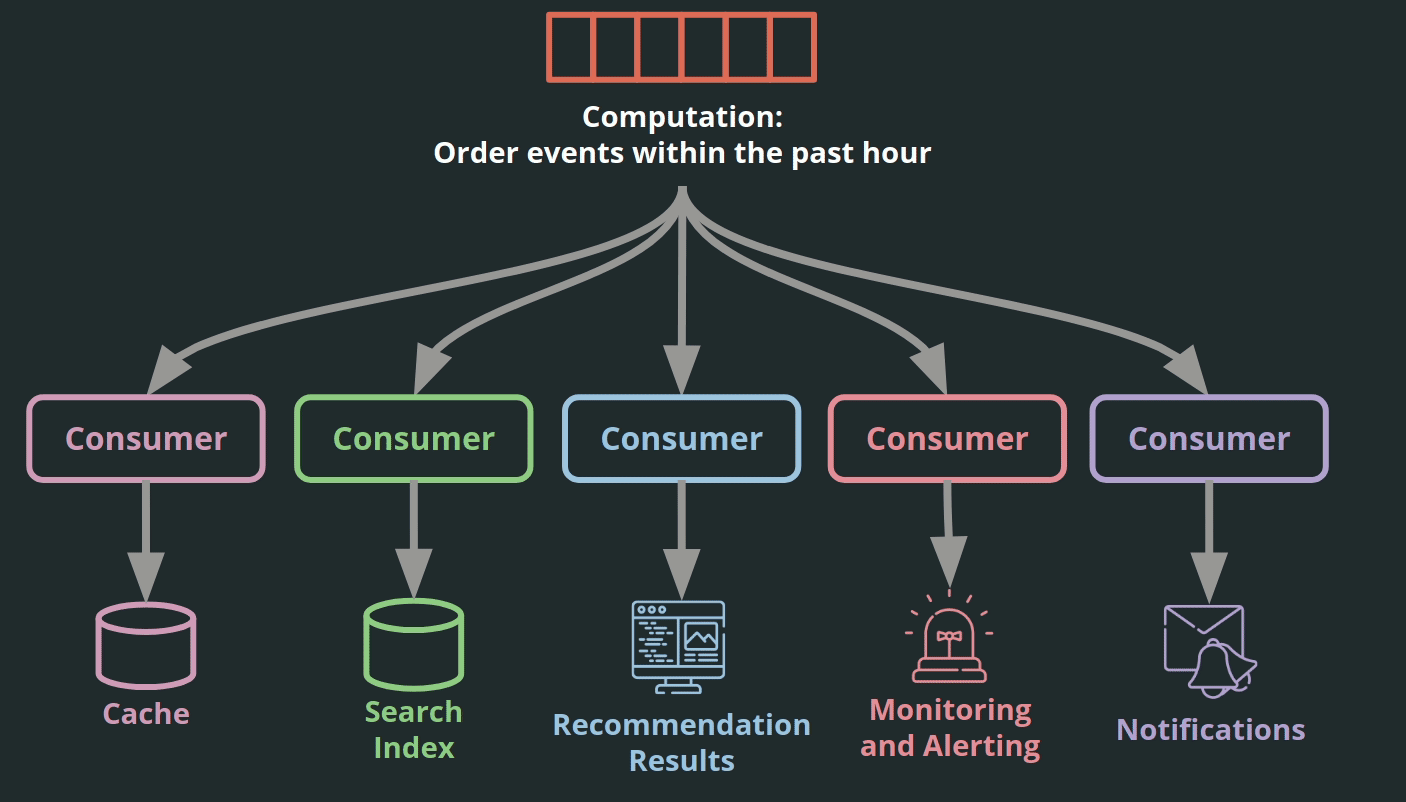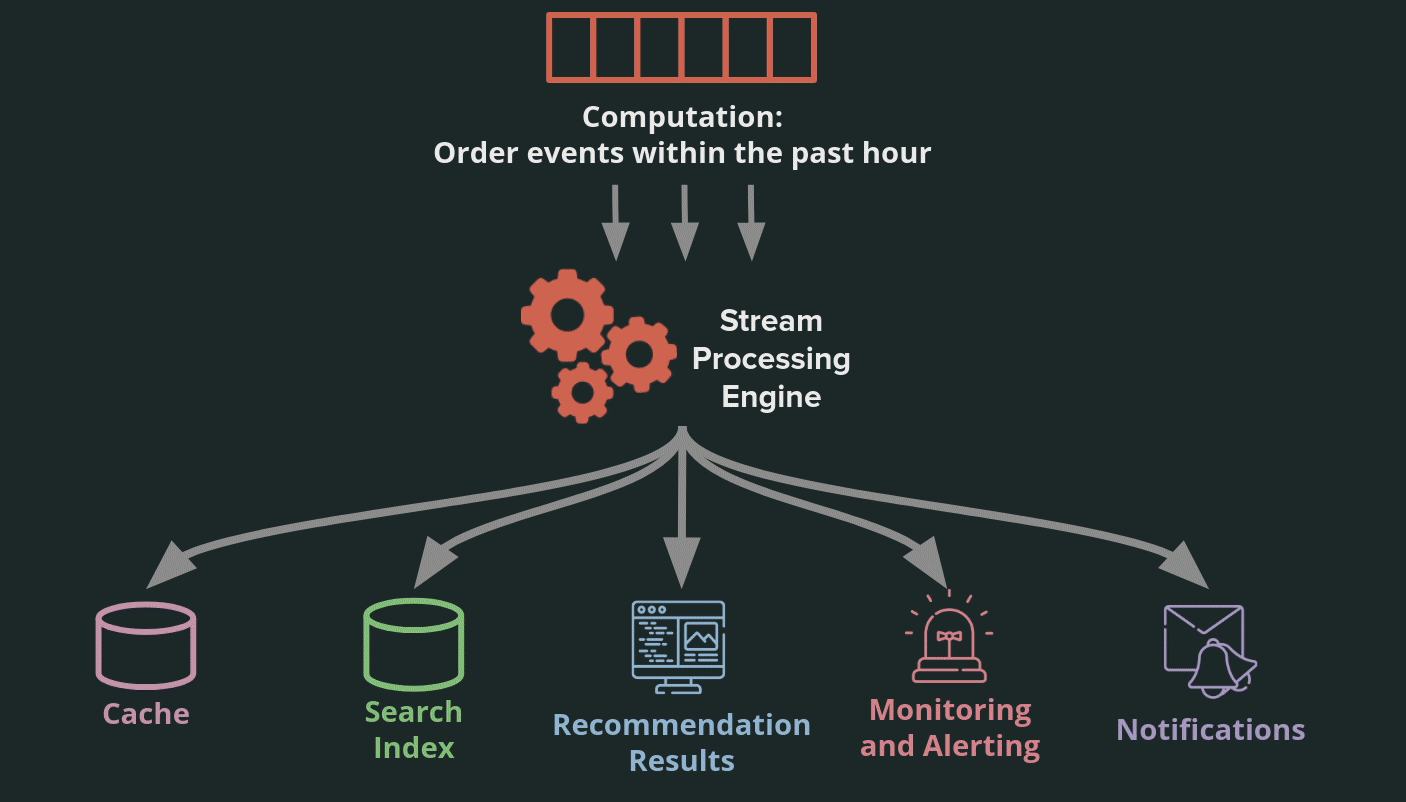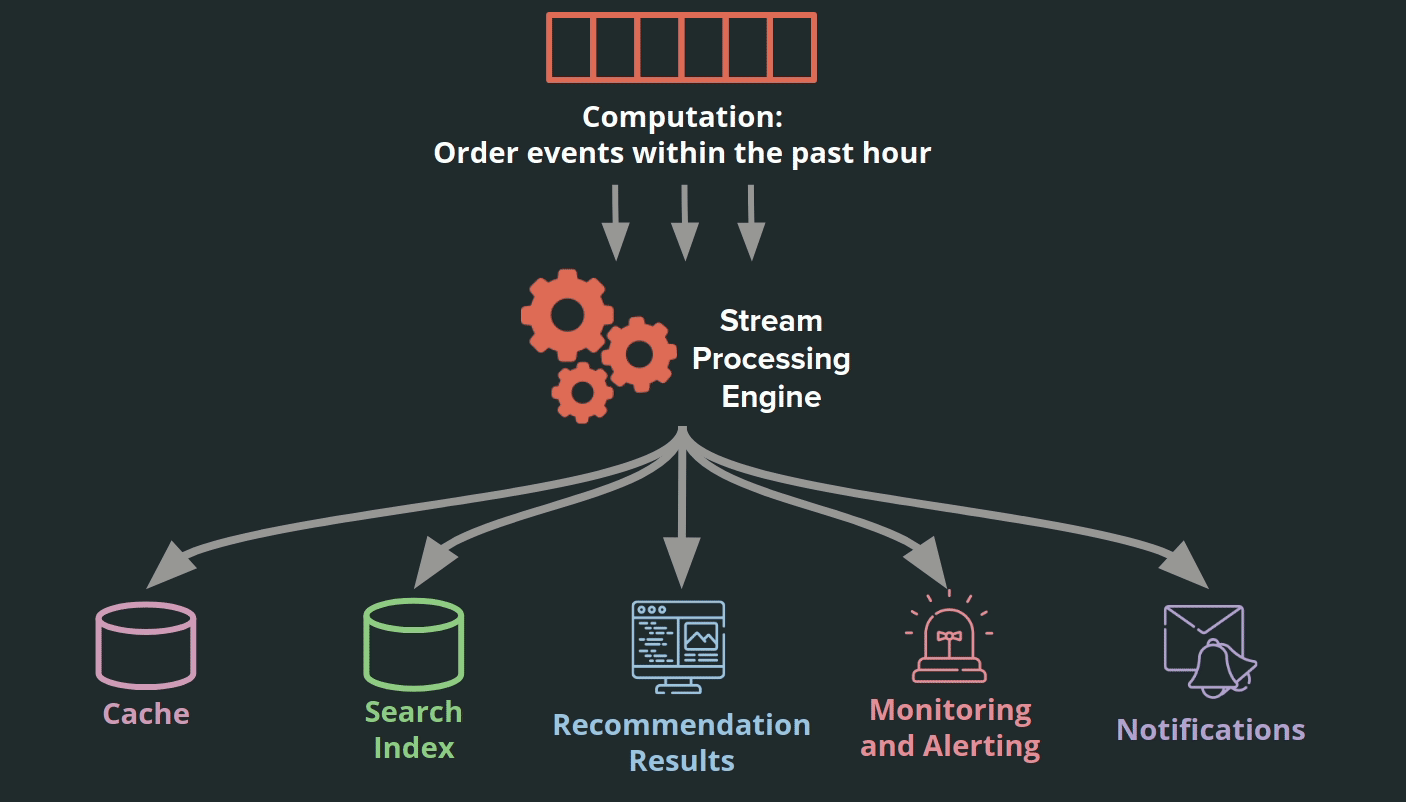
Adding a stream processor to a log-based architecture expands the benefits of the system. Services can write data efficiently by appending it to the log. The stream processor can complete operations shared by different services more efficiently. This means that services can share the same underlying data and easily transform that data into a format that is ideal for their needs.
2.4.1 A note on the importance of databases
This background emphasizes the benefits of an event-driven architecture with a distributed log at its core. However, event driven architecture does not replace databases completely.
Databases prioritize state, while events prioritize state changes. State is derived from events – for example, your physical location as you read this is the result of the event that moved you there. In an application, both events and state are useful. Databases in an architecture provide fast access to state.
A log-based, event-driven architecture utilizes distributed logs and databases to provide the benefits of both in a fault-tolerant and scalable way.
2.5 Summary
- In a microservices architecture, many services require access to the same data.
- Propagating data to many services is difficult with architecture centered on databases.
- Events can help address this problem. Events represent what happened in the application and when.
- Message brokers help move events between producers (data creators, such as an application) and consumers (services that need the data).
- Log-based message brokers can propagate data to services in real time in a fault-tolerant, consistent, and scalable way, and provide the flexibility to use historical data.
- Event stream processors abstract out common operations on event data to a fault-tolerant and scalable engine that maintains event order.
- An architecture with a distributed event log at its core and databases to store outputs provides fast access to both events and state. Multiple services can now use the same data in different ways, and the application has the agility to grow with changing requirements.
3. Venice
Venice is an open-source framework that enables developers starting out with event-stream processing to quickly deploy and manage an event-stream processing pipeline.
Venice is built for smaller applications and for developers with limited event-streaming knowledge. It uses open source components to set up a stream processing pipeline with reasonable default settings and simple management tools within minutes.
Large companies typically use stream processing to perform the following tasks:
- Process complex real-time event data to make applications more responsive.
- Detect anomalies in events.
- Deliver real-time analytics without interfering with the application’s ability to write new data.
The desire to perform these tasks, however, is not unique to large enterprises with applications that process millions of events per day. Any growing application might benefit from event stream processing. The implementation of these pipelines differs, but they have several interconnected components that achieve the following workflow:
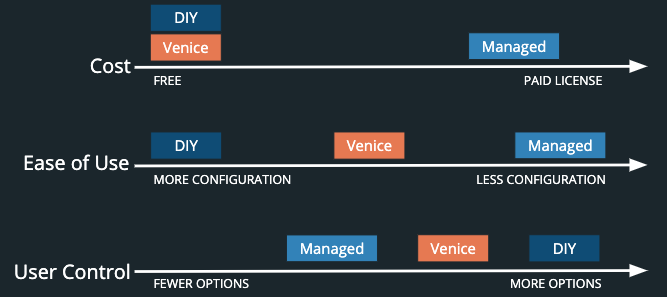
3.1 Venice sits between DIY and managed solutions
The existing choices available to developers roughly fall into two categories: managed solutions and do-it-yourself (DIY).
Managed solutions (such as Confluent’s Cloud Platform or Landoop) empower developers to focus on their applications by offering configuration guidance and on-going support for teams implementing streaming systems. However, they have high price tags, are generally designed for large enterprises, and can lock the team into using one vendor.
The DIY approach is an option for teams newer to this space. However, it trades monetary cost for complexity. First, application developers must deal with an abundance of choice. For the stream processing engine alone, there are multiple open-source options and several paid ones [Figure 12].

Second, because the stream-processing space is emerging, configuration tutorials become quickly outdated and documentation is minimal or challenging to parse. Choosing and learning how to configure a single component in the pipeline could take days or weeks. The problem compounds when attempting to learn which components best integrate together to form a pipeline with tradeoffs that are acceptable for the project.
Existing managed solutions and open source options may not be suitable for cost-conscious developers with limited streaming knowledge developing small streaming applications. Venice aims to be the middle ground - balancing the need for affordability, simplicity and control.
3.2 Design goals for an approachable stream processing framework
Venice is approachable for developers new to event-stream
processing.
It allows them to:
Set up common pipeline patterns in minutes so they can minimize time spent on configuration and focus on application code instead.
Retain extensibility and potential for reconfiguration if their needs change or become more complex.
4. Venice Implementation
Venice collects open-source components into a basic pipeline that developers can use with minimal configuration. It is stripped down to reduce troubleshooting headaches but filled with enough tools and features to help developers new to the space ramp up quickly. Venice allows teams to:
- Connect their own producer(s) or build from the available Venice producer.
- Process streaming data using SQL-like syntax.
- Connect consumers to the pipeline to read the processed data.
- Ensure consistency and correctness of data at all stages of the pipeline.
Each included component helps developers with these tasks.
4.1 Kafka is at the heart of the Venice pipeline
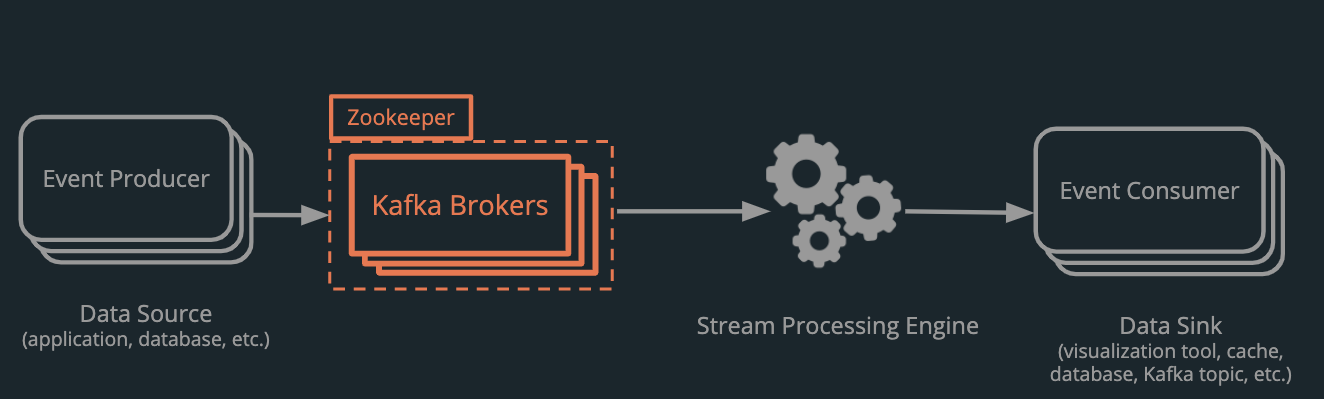
Kafka is a message broker built on a distributed append-only log and is by far the most popular open-source log-based message broker. It has a robust ecosystem, good documentation, and active development.
Venice has a three-broker cluster with partitions distributed across the brokers to enable higher throughput and fault tolerance via redundancy. This cluster is managed by an instance of Apache Zookeeper which handles tasks like leader elections.
Kafka is part of an event streaming ecosystem that includes some additional components used in Venice’s default pipeline:
- ksqlDB: an event streaming database that Venice uses primarily as an approachable stream processor.
- Kafka Connect: a framework for automatically copying data between Kafka and external systems.
- Confluent Schema Registry: a tool to validate and manage schemas.
The importance of these components is addressed in turn.
4.2 ksqlDB: a stream processor with SQL-like syntax
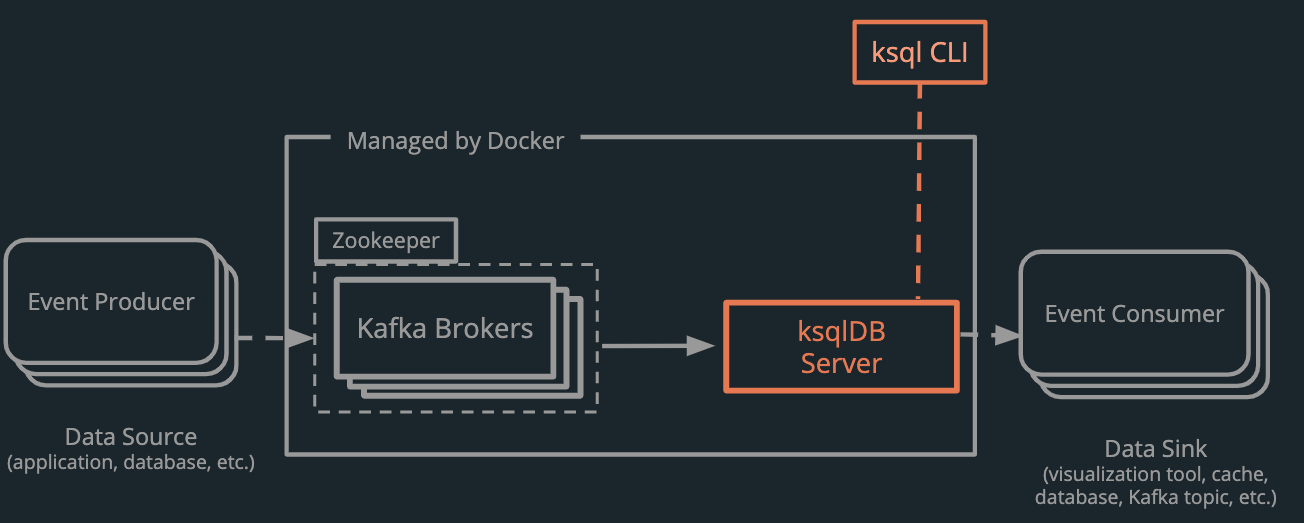
Event stream processing is complex. For developers new to the domain, there is a lot to learn. Venice keeps things as simple as possible. Many stream processing engines (Apache Spark, Apache Flink, Apache Kafka Streams) require developers to write event-stream processing tasks in Java or Scala. This presents a barrier to entry for developers unfamiliar with these languages. Additionally, several Java stream processing engines (Spark, Flink) require dependencies for Java JDK and Apache Maven. These introduce additional complexity that might make it more challenging for the Venice user to troubleshoot problems in the pipeline.
Venice implements ksqlDB as the primary stream processor. ksqlDB is not technically a stream processing framework, but an abstraction over the Kafka Streams stream processing library. ksqlDB provides much of the functionality of the more robust engines while allowing developers to use the declarative SQL-like syntax seen in Figure 16.

ksqlDB, with its support for a SQL-like syntax, allows developers to learn how to write streaming applications more quickly. ksqlDB has a CLI that Venice includes as an optional component. It is not available within the base Venice Docker pipeline but is easily accessible via the CLI.
It should be noted that Java- or Scala-fluent developers requiring higher complexity in their stream processing applications can still use the base Venice pipeline with Kafka Streams, which is simply a Kafka client library readily available to the system [8]. Developers with differing skill sets can use the pipeline in various ways to maximize their experience.
4.3 Connecting Consumers: Kafka Connect and PostgreSQL
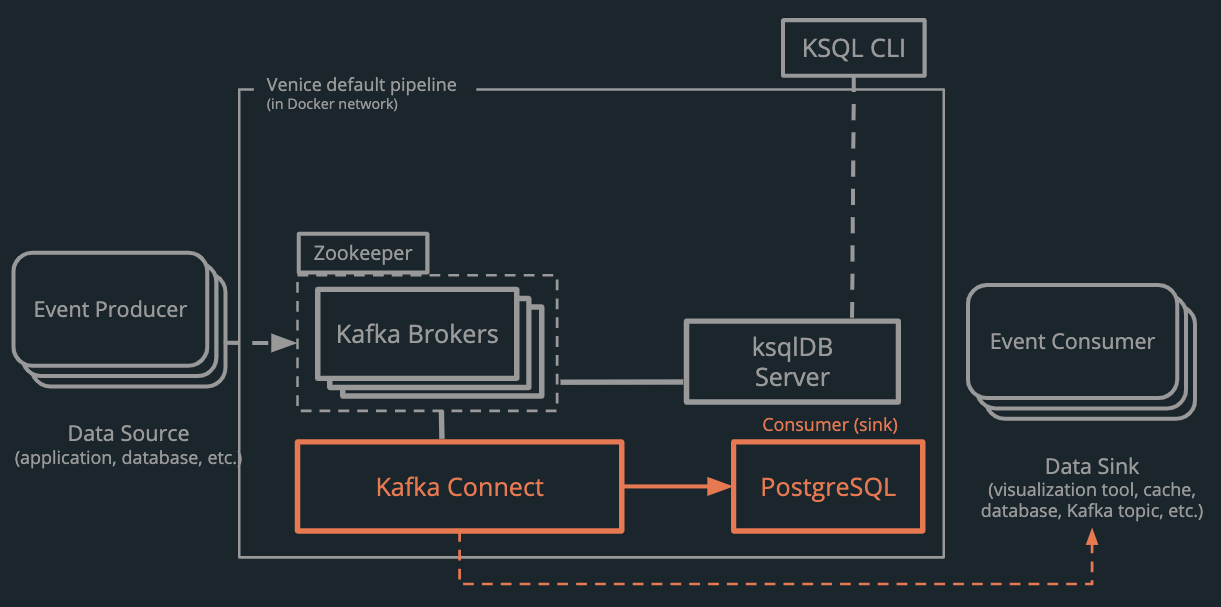
In a streaming application there are common patterns to consume data.
- Consume events directly from Kafka to perform real-time actions.
- Consume events automatically to keep a data store in sync with specific topic(s) on Kafka.
Venice is configured to enable both patterns as an application will often require a combination.
Pattern 1. Connect to Kafka Broker and Schema Registry directly.
ksqlDB writes the results of transformations back to Kafka as a new topic. As user can write consumer applications in the language of their choice1 that respond in real-time to the results of stream processing. For example, a user can filter high priority events into a new topic and have an application consume that topic.
1 There is the requirement that the chosen language can connect to Kafka and the Schema Registry and deserialize Avro. This capability is available in most popular languages [9].
Pattern 2. Use Kafka Connect to automatically send events to a data sink.
Kafka Connect is a framework for copying data between systems. Kafka Connect serves as a centralised hub for connectors that synchronize data between Kafka and various data stores. Sink connectors can be considered consumers - configured instead of written - to synchronize data between Kafka and a datastore. This is useful for:
- Ad-hoc queries that are too infrequent to run as stream processing jobs, but still benefit from up-to date data.
- Automatically syncing data to data stores like databases or caches.
Venice uses Kafka Connect in the default pipeline to connect to a PostgreSQL database. A user can sink any topic on Kafka to a new table in Postgres via the Venice CLI. The table will be updated as new events arrive in Kafka. Users can then perform ad-hoc queries on this database and know that the results will be in sync with the rest of their pipeline.
Confluent Hub hosts hundreds of Connectors for popular data sources and sinks that can extend the pipeline1.
Consuming real-time data from the pipeline is the overarching goal of an event-stream processing pipeline. Kafka Connect and PostgreSQL bolster the functionality of ksqlDB to ensure Venice meets the most common consumer patterns for a streaming application.
1 Adding additional connectors requires configuration of connectors, tasks, and convertors.
4.4 Confluent Schema Registry and Avro data format help provide data consistency and correctness for consumers
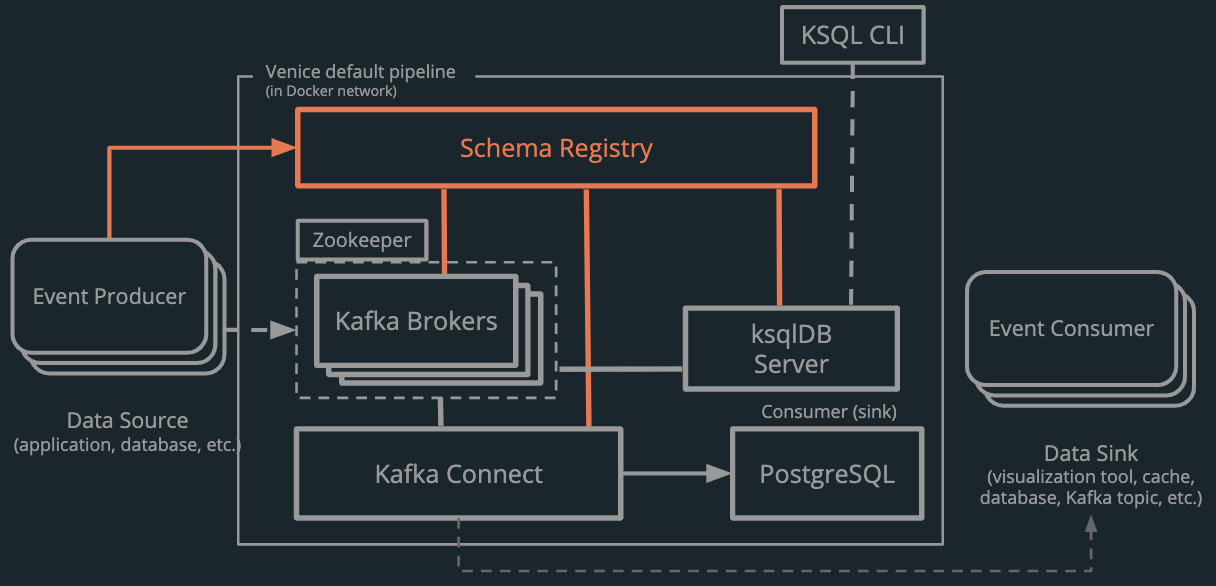
Kafka, ksqlDB, and Kafka Connect provide the previously-discussed functionality: ingest and store in the log, manipulate in the stream processor, and connect to output in the sink. Venice also includes the Schema Registry to help the entire system operate more smoothly.
Kafka does not enforce any particular format for event data beyond a simple key/value pair. Kafka is not aware of the data format as all records are stored as byte arrays. While Kafka doesn’t care about the data format, consumers do. Attempting to deserialize an event from byte array to the wrong data format is one of the most common problems when writing new consumers.
4.4.1 Confluent Schema Registry
The simplicity of Kafka comes from having all the data in one place and having all the data follow similar conventions. Venice includes the Confluent Schema Registry and encourages developers to use the open source Avro data format. These two tools bolster the benefits of Kafka by supporting data consistency and minimizing the data transfer burden on the network.
The Schema Registry exists apart from the Kafka brokers. Producers and consumers interact directly with Kafka to write and read data and concurrently communicate with the Schema Registry [Figure 19] to send and retrieve schemas.
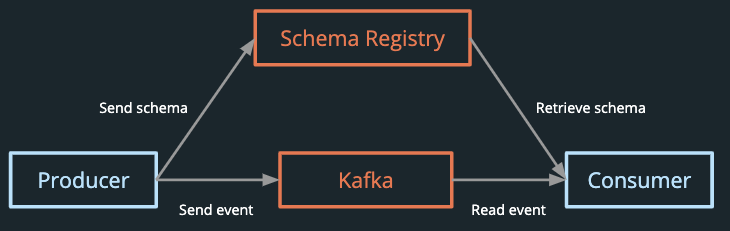
A schema registry provides three main benefits:
- Schemas are stored in one place. Any service requiring the data in a topic can request the schema.
- Schema changes are tracked. Tracking schema changes and when they occurred allows users to interpret and use all of the data.
- Schema validations can be performed. Data that does not conform to the schema can be rejected from the log. This prevents typos or incorrect data types from being written to the log.
4.4.2 Avro Data Format
Venice recommends users format their data using Avro [Figure 20]. Avro provides a rich schema definition language, integrates with the Confluent Schema Registry, and is sent efficiently over the network in a compact binary format [10].
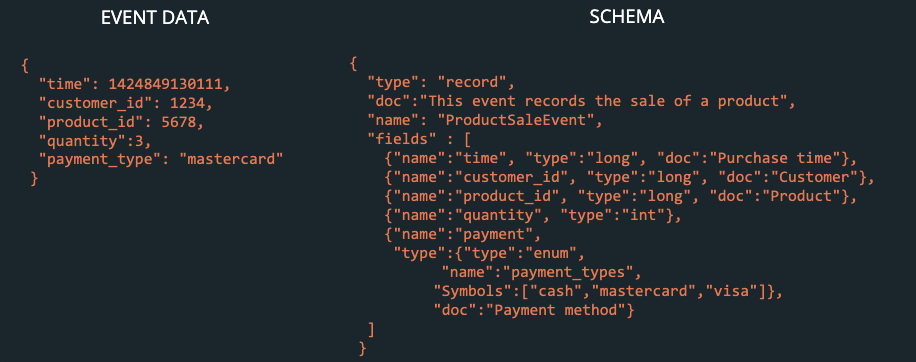
The Schema Registry doesn’t eliminate issues of consistency and correctness. That depends on how Venice users develop event producers and event-streaming queries. However, with this component users have a tool to reduce the risk of introducing incorrect or incompatible data in their pipeline.
The above four components - Kafka, ksqlDB, Kafka Connect, and the Schema Registry - provide the foundation of the Venice pipeline. They help make Venice flexible, extensible, and robust.
5. Architecture and Deployment
As explained in the previous section, Venice consists of these components:
- Kafka brokers for logging events
- A Zookeeper instance for managing the cluster of Kafka brokers
- A ksqlDB server for performing aggregations, filtrations, transformations, and joins over real-time data
- KSQL CLI for interacting with the ksqlDB server
- Kafka Connect workers for moving data in and out of Kafka and simplifying the process of adding new sources and sinks
- A PostgreSQL data sink for storing the data in multiple formats
- A Schema Registry for managing schemas
It also includes the following components to enhance the user's experience:
- Kafdrop UI for monitoring message brokers
- Venice CLI for deploying and managing the pipeline
The components are packaged in Docker containers, making them easy to build and deploy or swap for others to better meet changing developer needs.
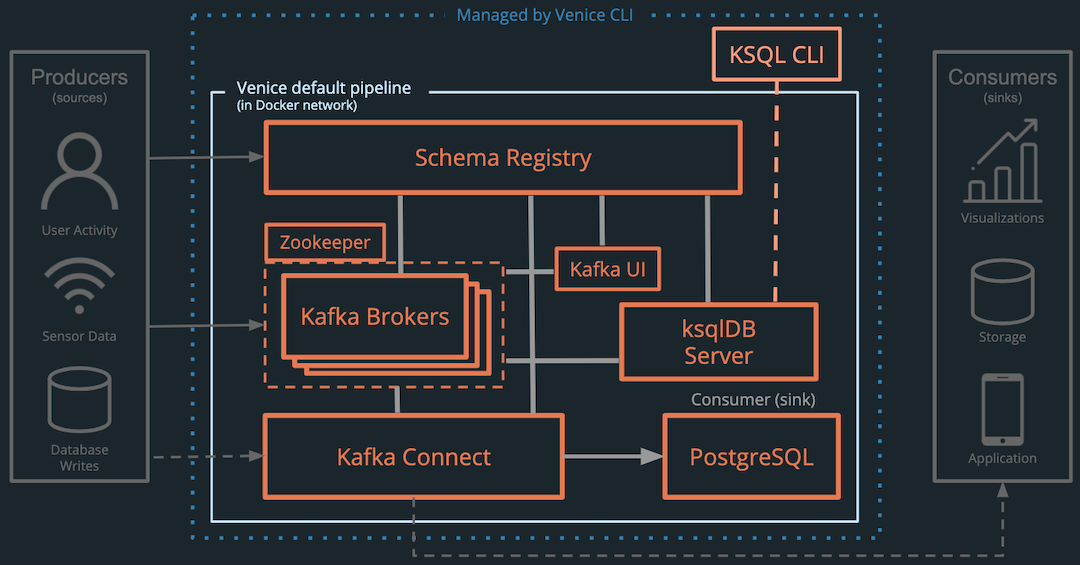
The workflow is as follows:
-
The user installs and launches Venice through the Venice CLI.

Figure 22. CLI commands venice installandvenice upin action. -
The user connects a producer which generates events and sends them
to the Kafka Brokers, which are managed by Zookeeper.
- Producers optionally register schemas with the Schema Registry.
- Additional producers can be configured to connect to the pipeline through Kafka Connect.
-
Kafka records the events in order and serializes them for
transport.
- The user can verify the serialization, topics, and more using the Kafka UI or Venice CLI.
-
The stream processing engine performs queries as it receives each
event and sends the transformed outputs back to Kafka to a new
Kafka topic.
- The user has the option of launching and using the KSQL CLI through the Venice CLI to add new queries to the ksqlDB server.
- Consumers can read directly from the Kafka Brokers, retrieving schemas from the Schema Registry to deserialize data.
- Kafka Connect connectors (PostgreSQL or additional optional user-added data sinks) synchronize data from Kafka to the database, automatically retrieving schemas from the schema registry.
Each of the components in the “Managed by Venice CLI” box runs within a separate Docker container.
5.1 Docker isolates pipeline components
The Venice pipeline contains multiple components and each has its own set of dependencies. These dependencies could conflict with each other or a user’s existing software. Docker isolates each component, preventing such dependency collisions. This provides streamlined installation as well as smoother addition of additional components.

5.2 Kafdrop provides visual insights to help manage stream processing pipelines
A source of complexity for a developer new to event stream processing is the difficulty of gaining insight into the system. For a developer new to stream processing it is often arduous to:
- Discover whether messages are being read and encoded properly or divided among partitions as desired.
- Schemas are registered or evolving as intended.
- Connectors are present and if their tasks are running or failed.
- Topics are available or created as requested.
To this end, Venice includes the third-party Kafdrop graphic user interface. Once a Venice user deploys the pipeline, they can navigate to a simple web interface that grants them a window into all of these features and more.
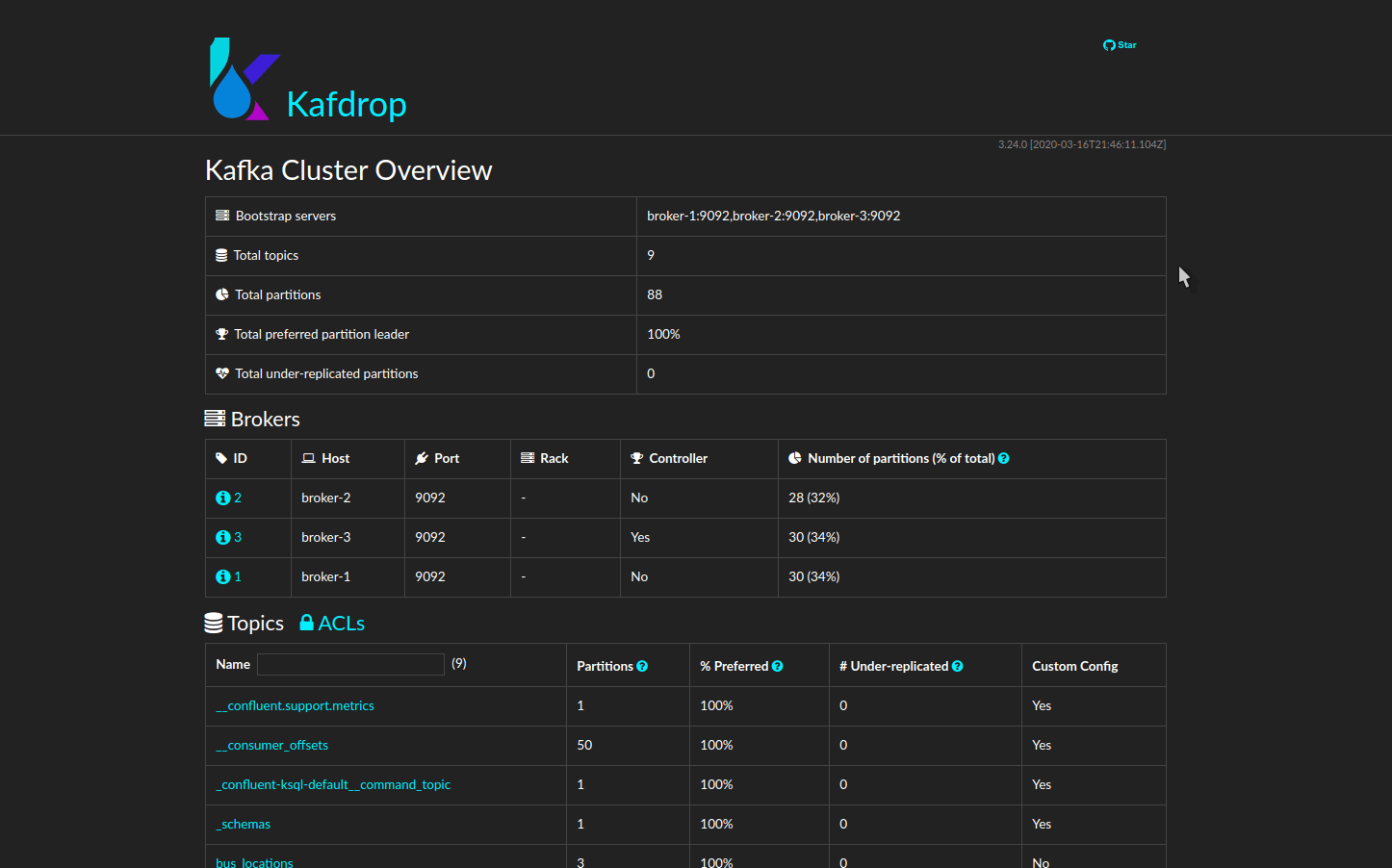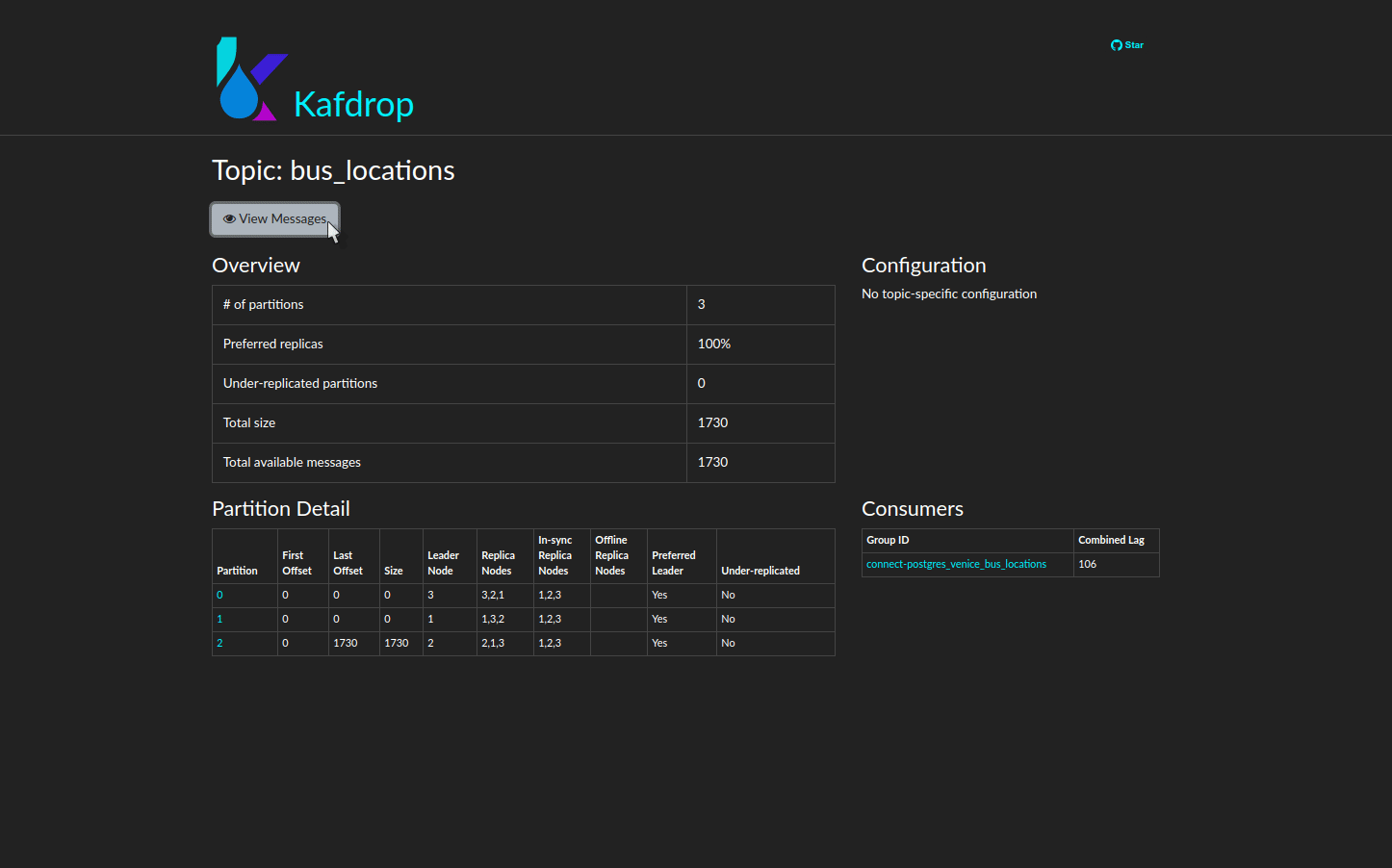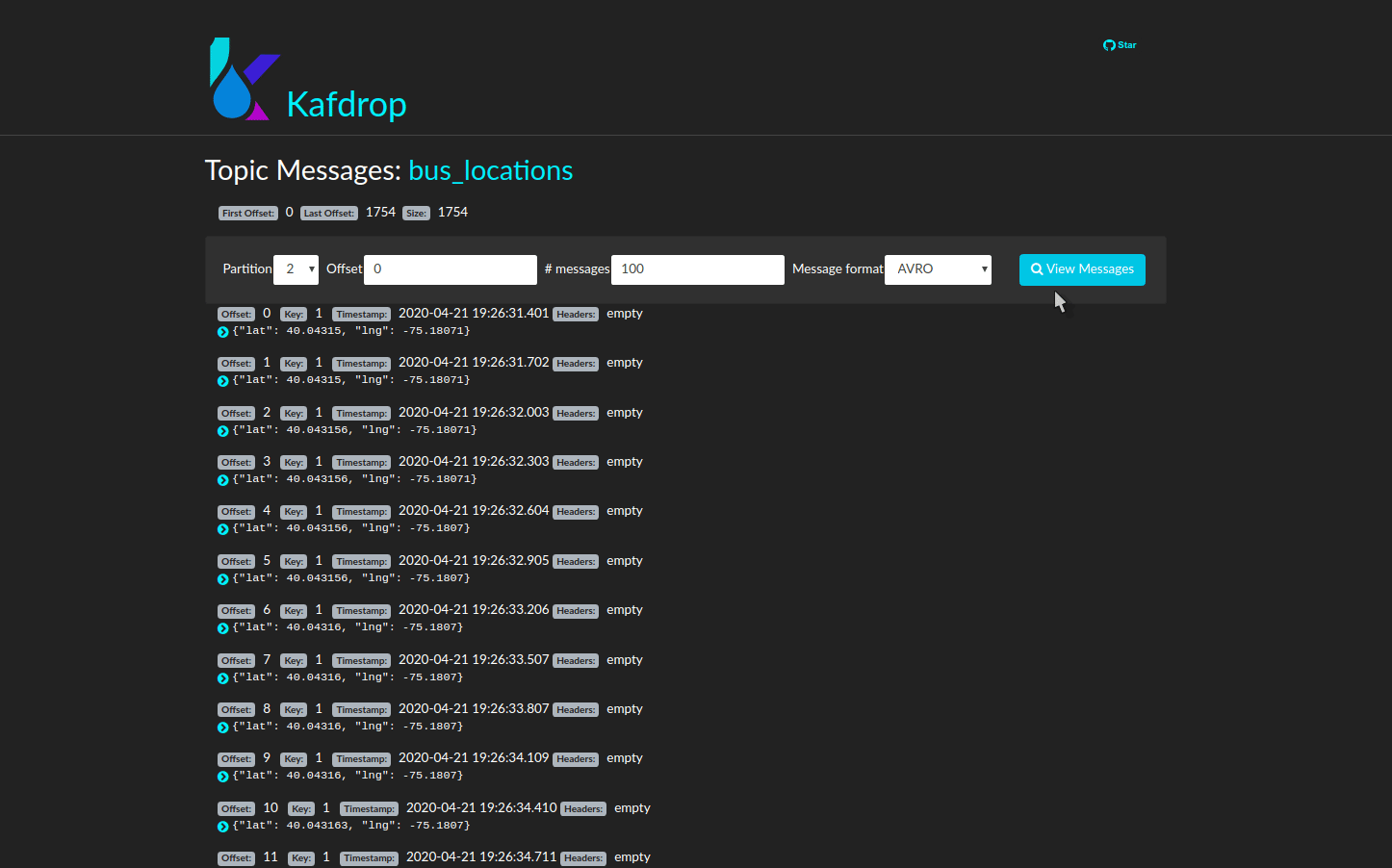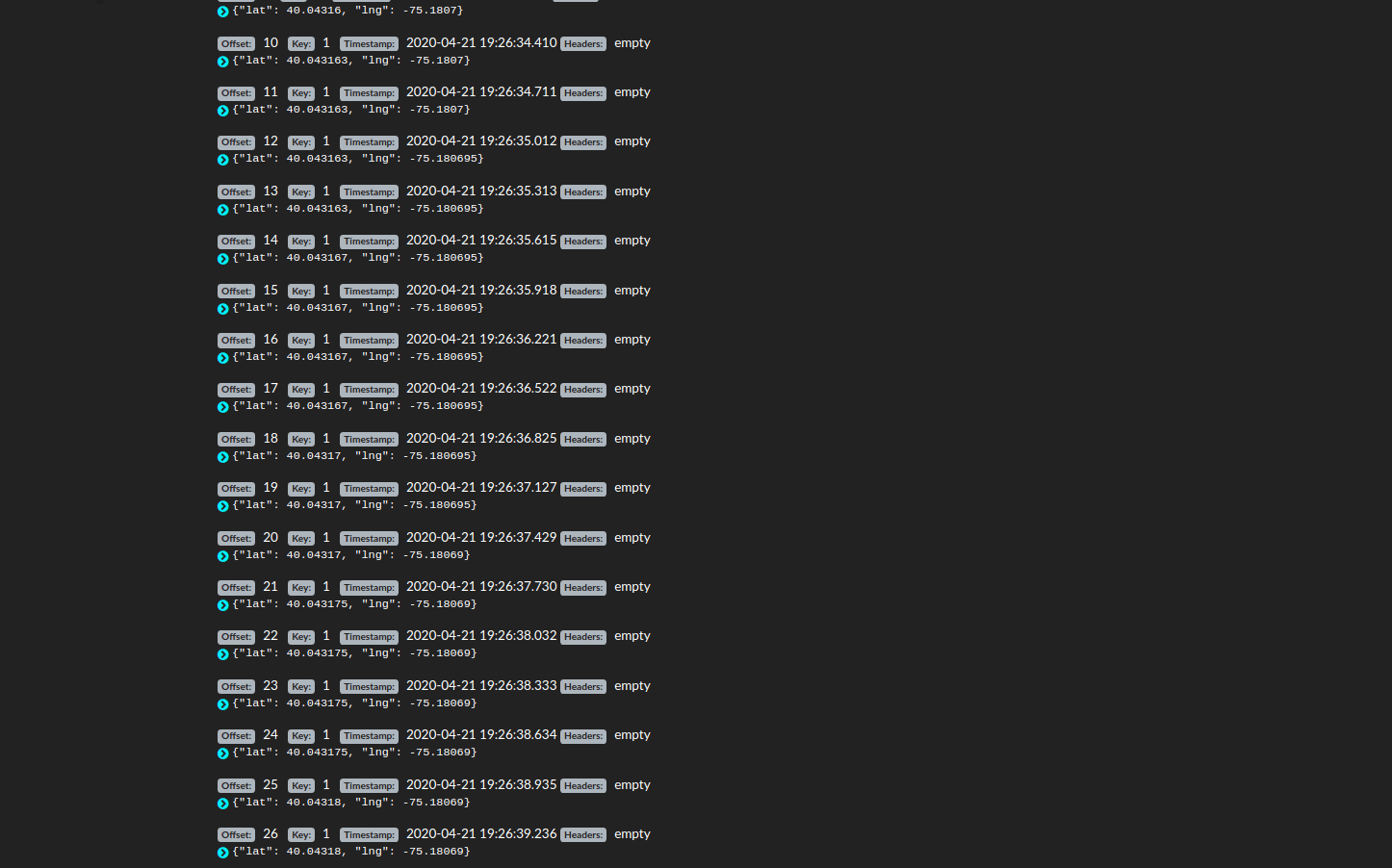
5.3 Venice CLI streamlines developer experience
The commands to interact with a containerized event streaming system can be a source of frustration. Many of the commands to manage the Venice containerized components are unwieldy and require an intimate knowledge of container names, ports, etc. Venice provides a CLI with 14 commands to streamline these interactions for developers.
Adminstrative Commands
| Command | Alias | Function |
|---|---|---|
down |
shut down the venice pipeline | |
install |
-i |
download / install a venice component from GitHub |
ksql |
-k |
launch the KSQL CLI |
logs |
-l |
view logs of venice components |
psql |
-p |
launch the postgreSQL CLI |
restart |
-r |
restart venice components |
schemas |
-s |
view schemas saved in the Schema Registry |
status |
-st |
view the status of venice components |
up |
launch the venice pipeline |
Connector Commands
| Command | Alias | Function |
|---|---|---|
connectors |
-c |
view existing connectors and their status |
connectors new |
-c new |
create a new connection to an existing data sink |
connectors delete |
-c delete |
delete an existing connection |
Topic Commands
| Command | Alias | Function |
|---|---|---|
topics |
-t |
view a list of the current topics |
topics show |
-t show |
view the event stream from an existing topic |
Figure 25. Commands for the Venice CLI
6. Challenges
Venice solves for several challenges: persisting data, reliably launching and connecting component containers, and consistently serializing data.
6.1 How can Venice persist data to make materialized views and new services possible?
This challenge has three parts: data persistence, storage choice, and log retention strategy.
6.1.1 How should Venice persist data?
Retaining events indefinitely in Kafka allows users to build new services or re-design existing services that can consume the entire history of events to recreate application state. This is a critical feature for teams new to streaming applications who will be experimenting to discover what works.
Docker provides two ways to persist data for containers - volumes and bind mounts.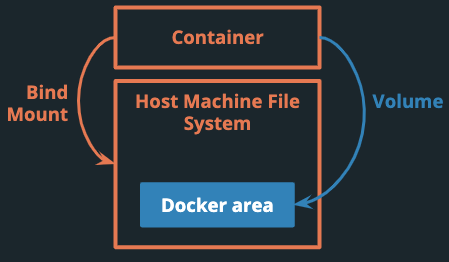
The main difference, shown in Figure 26, is where data is saved on the host machine. With volumes, Docker manages storing data in a restricted Docker directory. With a bind mount, a specific path on the host machine is loaded on the container at startup.
Venice uses bind mounts to ensure Docker loads a specific path from the host machine into the container everytime a container starts. When using volumes, new volumes are created when containers are re-configured and rebuilt. Bind mounts are a more reliable and consistent way of reloading data into the container for developers experimenting with new pipelines.
6.1.2 What is the optimal way for Venice to provide event persistence?
There are three options for persisting Kafka events indefinitely: permanent log retention, external backups, and compacted topics.
Choice 1: Permanent Log Retention
Typically, Kafka will delete events after a predetermined amount of time (e.g., 7 days) or when the log reaches a certain byte size. However, permanently preserving events is possible by overriding the default retention settings. A new consumer could then consume everything from the beginning of the log to derive the current state.
Choice 2: External Backup
Another option is to periodically copy older events to an external data store and remove them from Kafka. To recreate state for a new consumer, the backed up data must be reloaded and configured in Kafka.
Choice 3: Compacted Topics
Finally, log compaction refers to retaining the last known value for each message key within a single topic partition. Compaction guarantees event order by only removing older events whose state has changed.
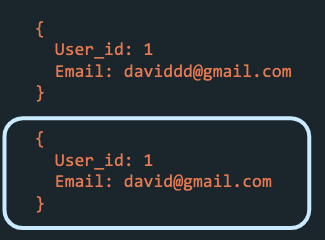
user_id: 1 is retained.
For example, Figure 27 shows events that track a change to a user’s email, where the user_id is the key. With a compacted topic, Kafka would guarantee that the most recent update to the email would be kept in the log.
Log compaction can be suitable for some topics. However, it means losing the ability to recreate state, leaving only the option to restore the latest state.
Venice: Permanent Log Retention
Venice uses permanent log retention because (1) it is a simpler solution than external backup, and (2) log compaction does not not fulfill the goal of extensibility. A compacted topic means users would not be able to consume historical data.
Permanent log retention is a safe option: users have all of their events stored by default, but they can choose to turn on log compaction for individual topics if they decide that is appropriate for their use case.
However, as a user’s application grows and events accumulate, they may want to consider external backup to free up space on the machines running the brokers.
6.2 How can Venice reliably launch and connect containers?
Each component in the Venice pipeline launches in its own container. This poses a few challenges.
6.2.1 How can Venice launch all of the containers with a single command?
A user would likely want to experiment with their pipeline, which means they would be starting and stopping the entire pipeline multiple times. Docker Compose allows Venice to define all of the pipeline components in a single YAML file and specify the startup order. A single command would start and stop all of the containers.
6.2.2 How can containers securely and reliably communicate with each other?
Docker Compose automatically creates a network for all components defined in the YAML file. This network enables communication between containers while isolating them from the host network. However, the name of this automatically generated network is dependent on the name of the directory where the YAML file is located[11, 12]. For example, if the directory was called “venice”, the name of the default network would be “venice_default”.
The Venice CLI needs to work with components on the network regardless of the names of the directories, so it uses Docker Compose’s custom networks feature to define a network named “venice”.
6.2.3 How can Venice address race conditions between containers?
Venice can dictate the startup order for each container, but sometimes this is not enough [13]. Just because a container is running does not mean it is listening on a port or ready to send or receive messages.
Two problems stemming from this are:
- Producers crash if they attempt to connect to the Schema Registry before it is ready.
-
The Venice
connector-initservice fails to initialize stored connectors on startup if Kafka Connect is not ready.
Venice solves these dependency issues with shell scripts that ping for confirmation that the Schema Registry and Kafka Connect are ready to receive connections before running producers or initializing connectors [14].
6.3 What default serialization format should Venice recommend?
Venice encourages developers to use Avro but Avro keys are incompatible with ksqlDB.
In Kafka, each event key and value is written as a pair of raw bytes. If a producer serializes the event in one format and the consumer deserializes it in another, the application will produce errors or the data will be unusable [Figure 28].

ksqlDB requires STRING event keys, but the default
configuration for many connectors is Avro keys and values. Encoding
the key as a STRING and the value in Avro allows users
to leverage all of ksqlDB’s functionalities while retaining many of
the benefits of using Avro (since values typically contain more data
than keys).
7. Future Work
Venice meets many of the needs of developers new to event-stream processing. Venice provides a quick-to-deploy framework that has much of the configuration work automated. This means developers can get to their tasks of connecting their own data producers and implementing queries over their data in minutes. They can also verify things are running smoothly using the graphical user interface and CLI.
However, there are always areas for improvement. The following goals would likely add the most value to Venice:
- Automate deployment and management across distributed servers
- Enable auto-scaling (up and down) according to workload
- Add more default pipelines
- Add support for more connectors
- Enable external network storage
- Automate the process of adding producers to the pipeline
8. References
- S. Newman, Building Microservices, 1st ed. Sebastopol, CA, USA. O’Reilly, 2015. ↩︎
- M. Kleppman, Making Sense of Stream Processing, 1st ed. Sebastopol, CA, USA. O’Reilly, 2016. Fig. 2 ↩︎ 2.1 p.5 ↩︎ 2.3.2 ↩︎
- “Consensus Protocols: Two-Phase-Commit”, The Paper Trail blog, https://www.the-paper-trail.org/post/2008-11-27-consensus-protocols-two-phase-commit/ (April 13, 2020). ↩︎
- M. Kleppmann, Designing Data Intensive Applications, 1st ed. Sebastopol, CA, USA. O’Reilly, 2017. 2.2 p.1 ↩︎ 2.2 p.3 ↩︎ 2.3.1 ↩︎ 2.3.2 ↩︎ 2.3.3 ↩︎
- J. Kreps, “It’s Okay To Store Data In Apache Kafka”, Confluent.io blog, https://www.confluent.io/blog/okay-store-data-apache-kafka/ (April 16, 2020). ↩︎
- T. Akidau, S. Chernyak, and R. Lax, Streaming Systems, 1st ed. Sebastopol, CA, USA. O’Reilly, 2018. ↩︎
- J. Kreps, “Introducing Kafka Streams: Stream Processing Made Simple”, Confluent.io blog, https://www.confluent.io/blog/introducing-kafka-streams-stream-processing-made-simple/ (April 14, 2020). ↩︎
- D. Traphagen, “Kafka Streams and ksqlDB Compared - How to Choose”, Confluent.io blog, https://www.confluent.io/blog/kafka-streams-vs-ksqldb-compared/ (March 20, 2020). ↩︎
- Apache Kafka documentation: Kafka Clients, https://cwiki.apache.org/confluence/display/KAFKA/Clients (April 13, 2020). ↩︎
- J. Kreps, “Why Avro for Kafka Data?”, Confluent.io blog, https://www.confluent.io/blog/avro-kafka-data/ (April 15, 2020). ↩︎
- Docker documentation: Docker Compose, https://docs.docker.com/compose/ (April 12, 2020). ↩︎
- Docker documentation: Docker Compose networking, https://docs.docker.com/compose/networking/ (April 12, 2020). ↩︎
- Docker documentation: Docker Compose startup order, https://docs.docker.com/compose/startup-order/ (April 10, 2020). ↩︎
- R. Moffatt, “Docker Tips with KSQL and Kafka”, Professional Blog of Robin Moffatt, https://rmoff.net/2018/12/15/docker-tips-and-tricks-with-ksql-and-kafka/ (April 9, 2020). ↩︎