Documentation
What is Venice?
Venice is an open-source framework that enables users to deploy and manage stream processing pipelines.
Venice is designed for users who want to set up a streaming pipeline with minimal hassle, and may be most suitable for developers who want to quickly deploy a streaming pipeline for a small application.

Features
Venice’s main features are:
- An easy to use command line interface for common development and pipeline management tasks.
- A default pipeline to quickly support stream processing applications.
- Simple configuration of new connections and components.
- A web-based UI for monitoring the message brokers.
Components
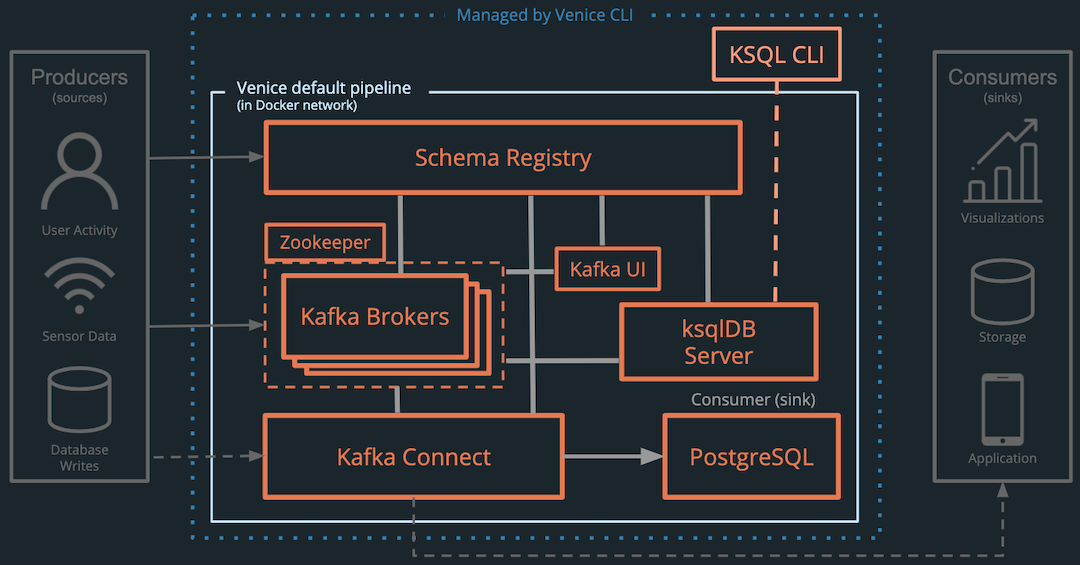
The Venice default pipeline consists of multiple components:
- Kafka brokers for logging events
- Zookeeper for managing the Kafka brokers
- Confluent Schema Registry for managing schemas
- ksqlDB and ksqlCLI for performing aggregations, filtration, transformations, and joins over real-time data
- Kafka Connect for pushing data into and pulling data out of Kafka and for simplifying the process of adding new sources and sinks
- PostgreSQL data sink for storing or presenting the data in multiple formats
- Kafdrop Kafka UI for visually inspecting messages, schemas, and connectors
The components used in the pipeline are packaged in Docker containers, making them easy to build and deploy or swap for others to better meet your needs.
To learn why we chose these components, read our Case Study
Architecture
When does it fit?
Venice offers a middle ground between proprietary and DIY solutions (more details here). Venice is open-source, abstracts away some of the complexity, comes with reasonable defaults, and is fully customizable and extensible. It may be most suitable for a subset of users.
Venice may be a good fit if:
- You want to start with a basic stream processing pipeline for a small application.
- Most of the default settings would work for your use case.
When does it not fit?
Venice may NOT be a good fit if:
- Your application has to handle a large volume of events.
- Your use case is complex and requires substantial customization.
Quickstart
Installation Instructions
Dependencies
- Node (the CLI was created and tested with version 13.8.0)
- npm (the CLI was created and tested with version 6.13.6)
Install Venice CLI
Use this command:
git clone https://github.com/venice-framework/venice-cli.git &&
cd venice-cli && npm install && sudo npm link
Or do it step-by-step:
-
Clone the respository.
git clone https://github.com/venice-framework/venice-cli.git -
Navigate into the newly installed
venice-clidirectory.
cd venice-cli -
Install packages.
npm installornpm i -
Create a symbolic link.
sudo npm link
Choose a pipeline
Navigate to a repo containing a pipeline, or install a Venice default pipeline.
You can use the Venice pipeline with a PostgreSQL sink if you do not have a pipeline you want to test.
NOTE: The following command will clone a repo into the current
working directory. If you want the repo to be cloned into another
folder, navigate away from venice-cli now (e.g., `cd ..)
venice install
Select "venice - Base pipeline with a Postgres sink".
cd venice-postgres-sink
Add a producer
You can use your own or a Venice producer example.
Open the docker-compose.yml file in a text editor.
Uncomment the section for the producer so that
producer aligns vertically with the other services.
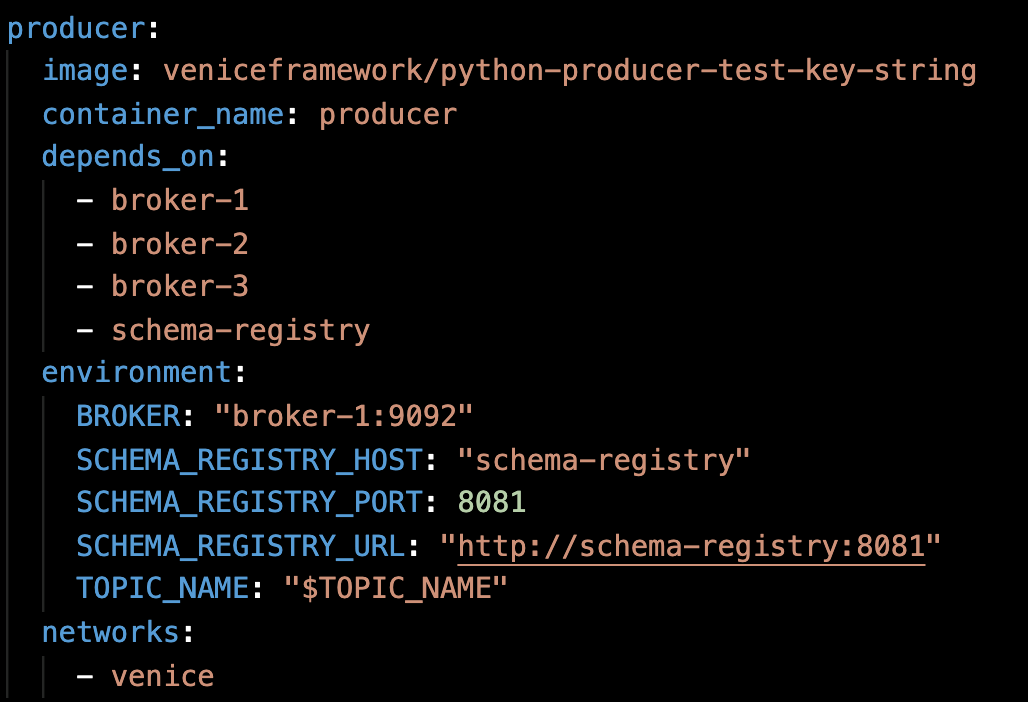
If you want to use your own producer, package it in a container and
have it use the environment variables
BROKER, TOPIC_NAME, and
SCHEMA_REGISTRY_URL. Then, swap out
image: veniceframework/python-producer-test-key-string
for the image you want to use.
Choose whether to insert or upsert the data into PostgreSQL
Open the docker-compose.yml file in a text editor if it
is not yet open.
insert inserts every row into the table.
upsert adds a new row if a row with the same key does
not exist yet. If a row with the same key exists, that row is
updated.
The PostgreSQL pipeline uses upsert by default. Within
the commands for the connector-init service, change
upsert to insert if you want to use
insert instead.
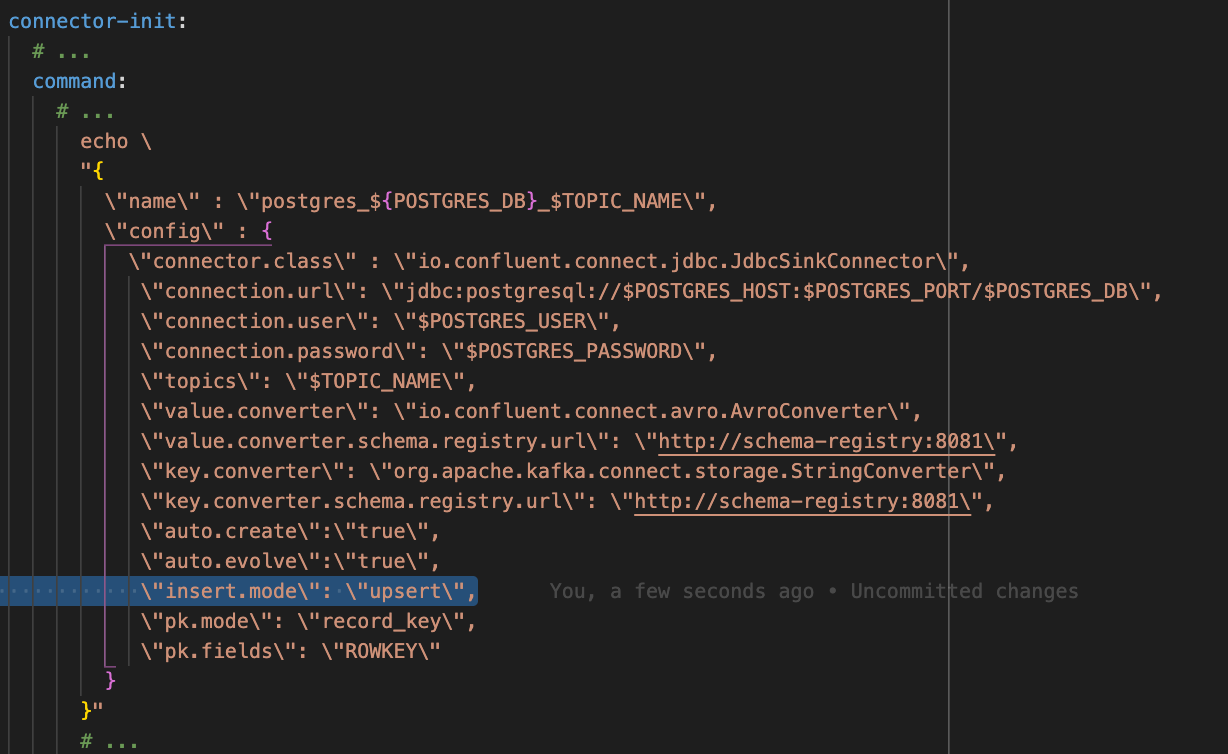
Save and close the file.
Change the topic name and PostgreSQL environment variables.
Open the .env file in a text editor. If you are
following along with the Venice producer and PostgreSQL pipeline,
change the values for TOPIC_NAME to
bus_locations and POSTGRES_DB to
buses. Save and close the file.
Start the pipeline.
venice up
Show the status of all components of the pipeline.
venice status or venice -st
To follow the logs of one or more components
venice logs
press space bar to select before pressing enter/return

venice logs demo
The output is piped to less, so you can navigate up and
down through the logs using the arrow keys or j and
k. Use the spacebar to scroll down by “page”, and press
q to quit.
Show topics, schemas, and connectors
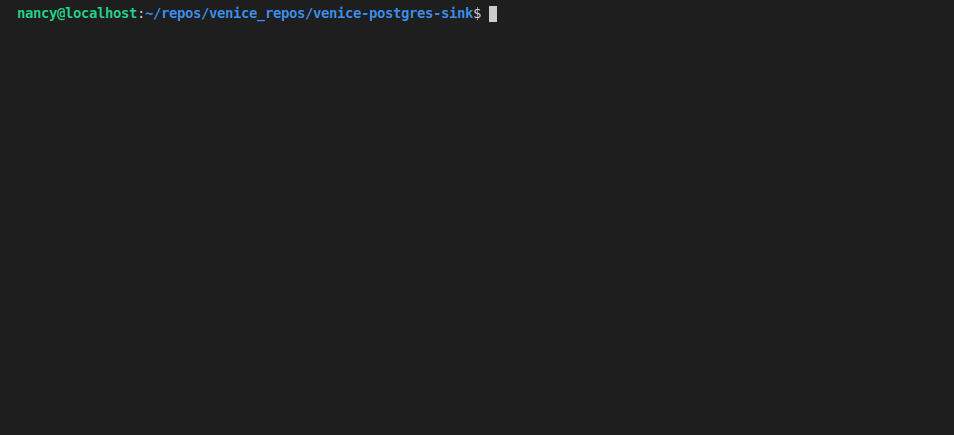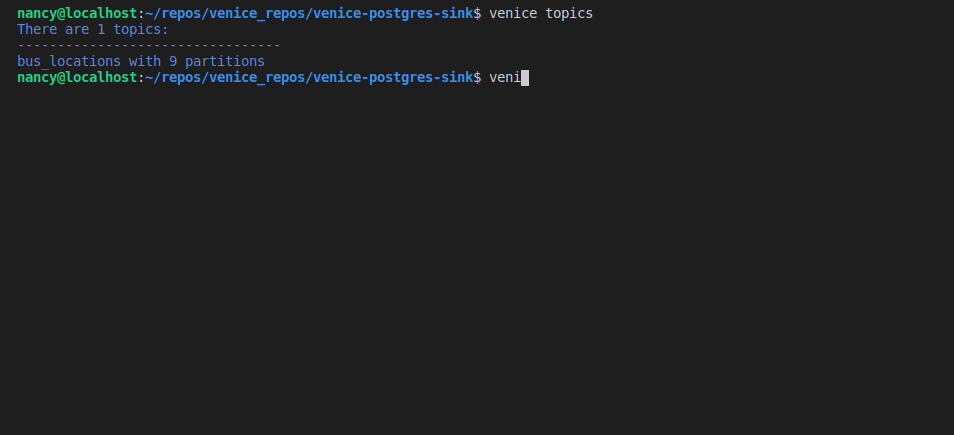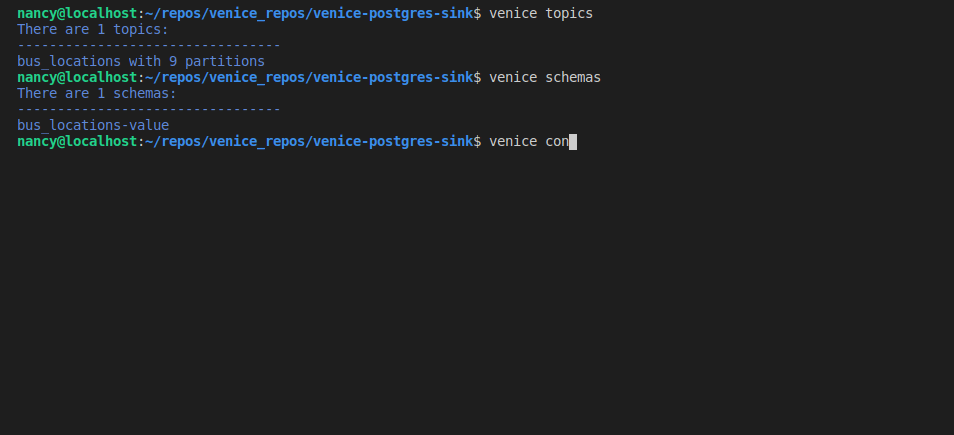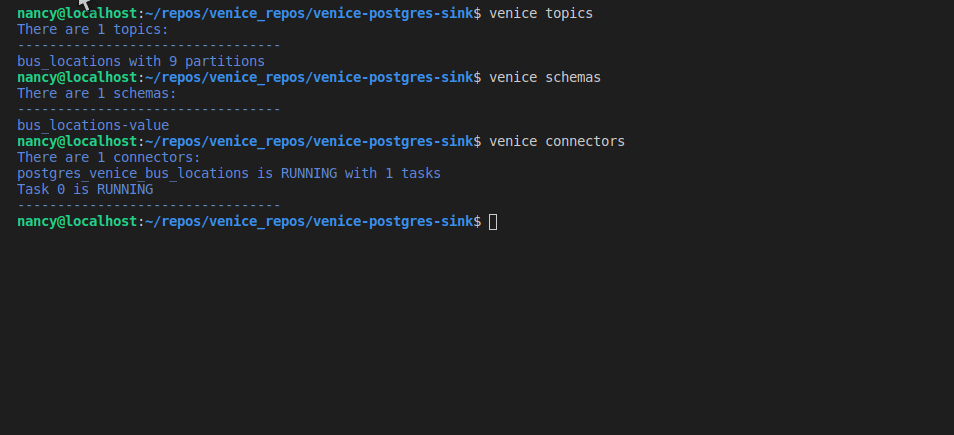
venice topics or venice -t
venice schemas or venice -s
venice connectors or venice -c
Open the KSQL CLI to see the data being written to the topic.
This will download the KSQL CLI if you have not already used it. There will be a notable delay as it loads for the first time.
venice ksql
If you get an error message that
Remote server at http://ksql-server:8088 does not appear to be a
valid KSQL server, exit the KSQL CLI and try again.
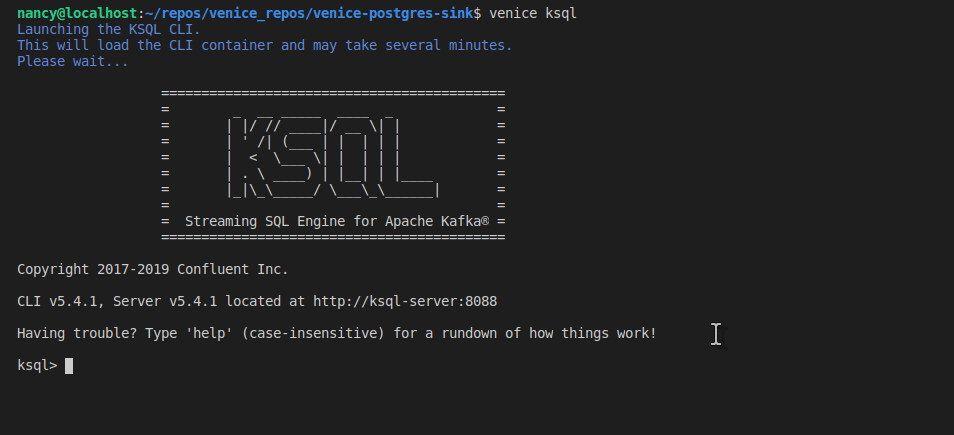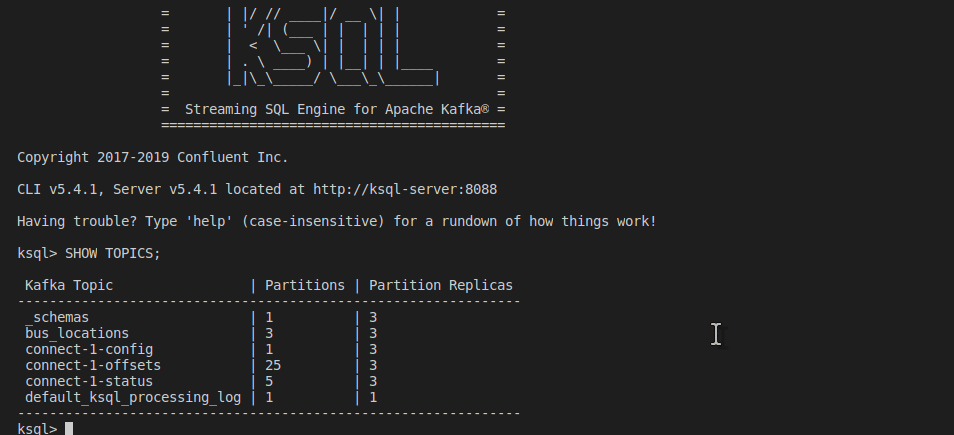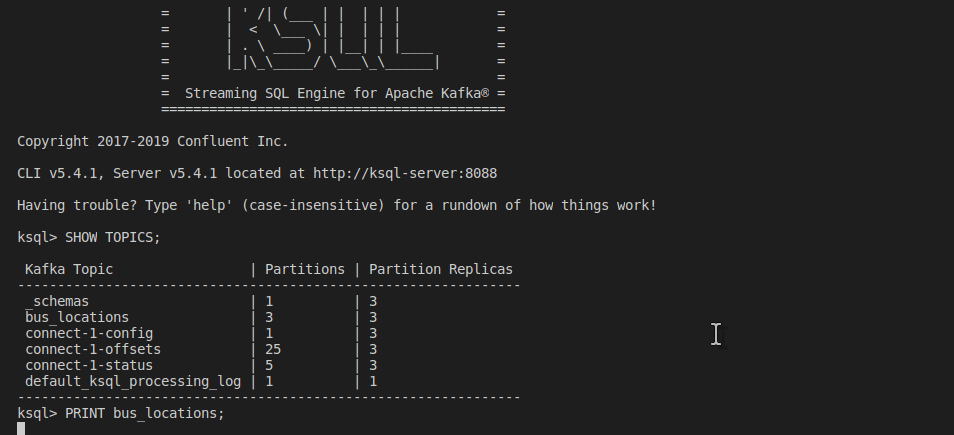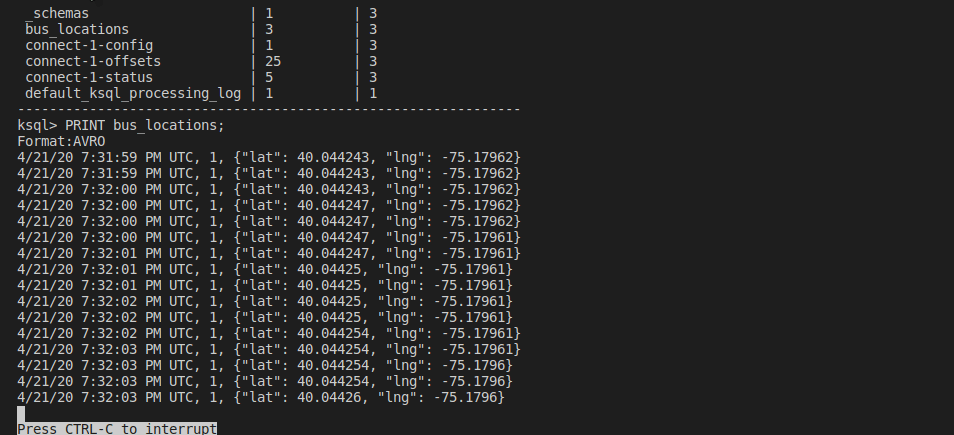
SHOW TOPICS and PRINT bus_locations KSQL
commands.
Try these KSQL commands: Show all topics. You should see
bus_locations among the list of topics.
SHOW TOPICS;
Print all data from the beginning.
PRINT bus_locations FROM BEGINNING;
Follow any new input.
PRINT bus_locations;
CTRL+C to stop printing.
You can issue additional queries over the data such as aggregations and other transformations. See more KSQL commands in the KSQL documentation
CTRL+D to exit the KSQL console.
Launch the PostgreSQL CLI to see the data populating in the database.
venice psql
If you are following along with the bus example, enter “venice_user” for the name of the PostgreSQL user, and “buses” for the name of the PostgreSQL database.
PostgreSQL commands:
-
Show all tables. You should see
bus_locations.
\dt -
Show the first ten rows.
SELECT * FROM bus_locations LIMIT 10; -
Display a count of how many records there are in the table.
SELECT COUNT(*) FROM bus_locations; -
CTRL+Dto exit the PSQL console. You can also useexit,quit,\q, orCTRL+C.
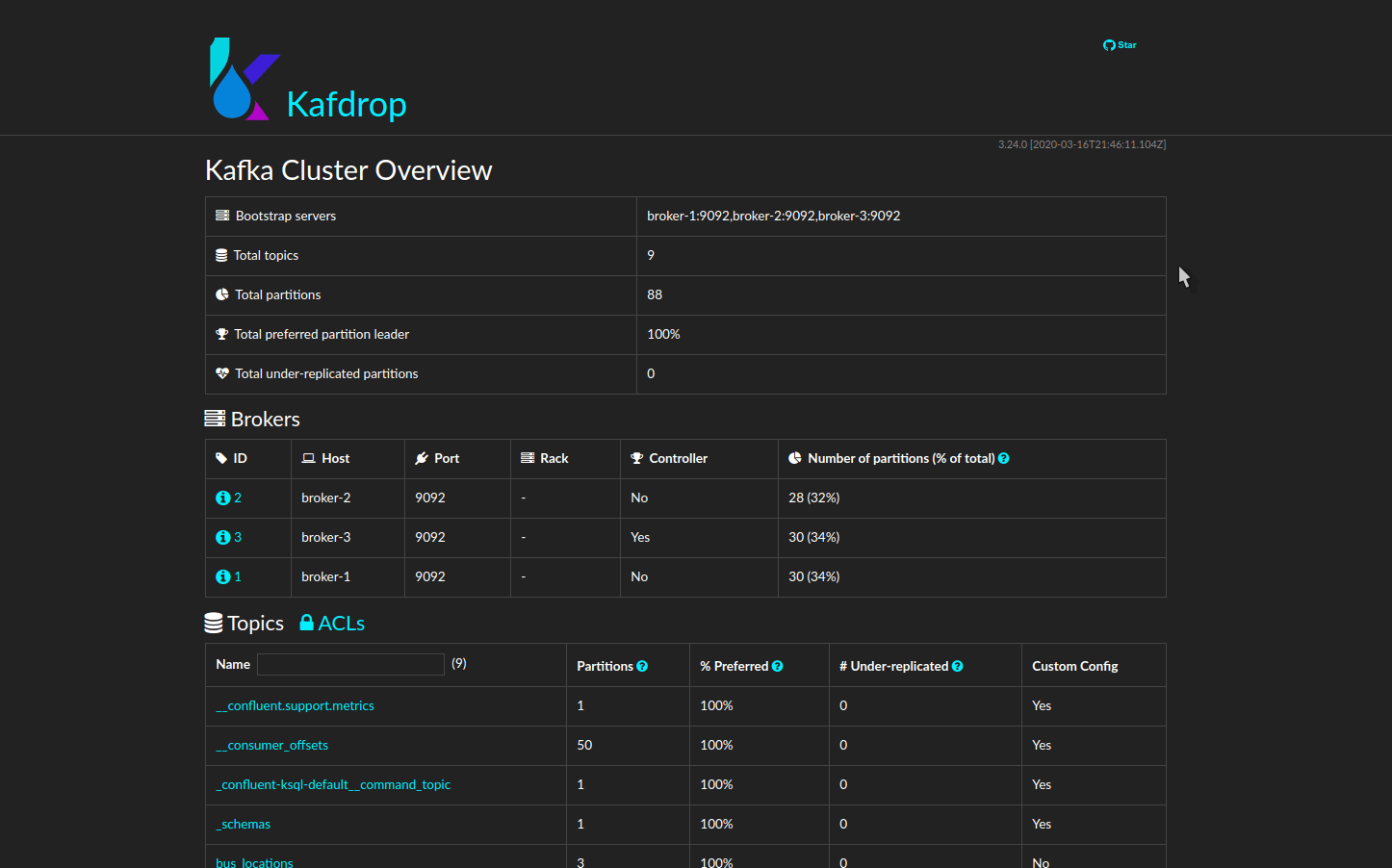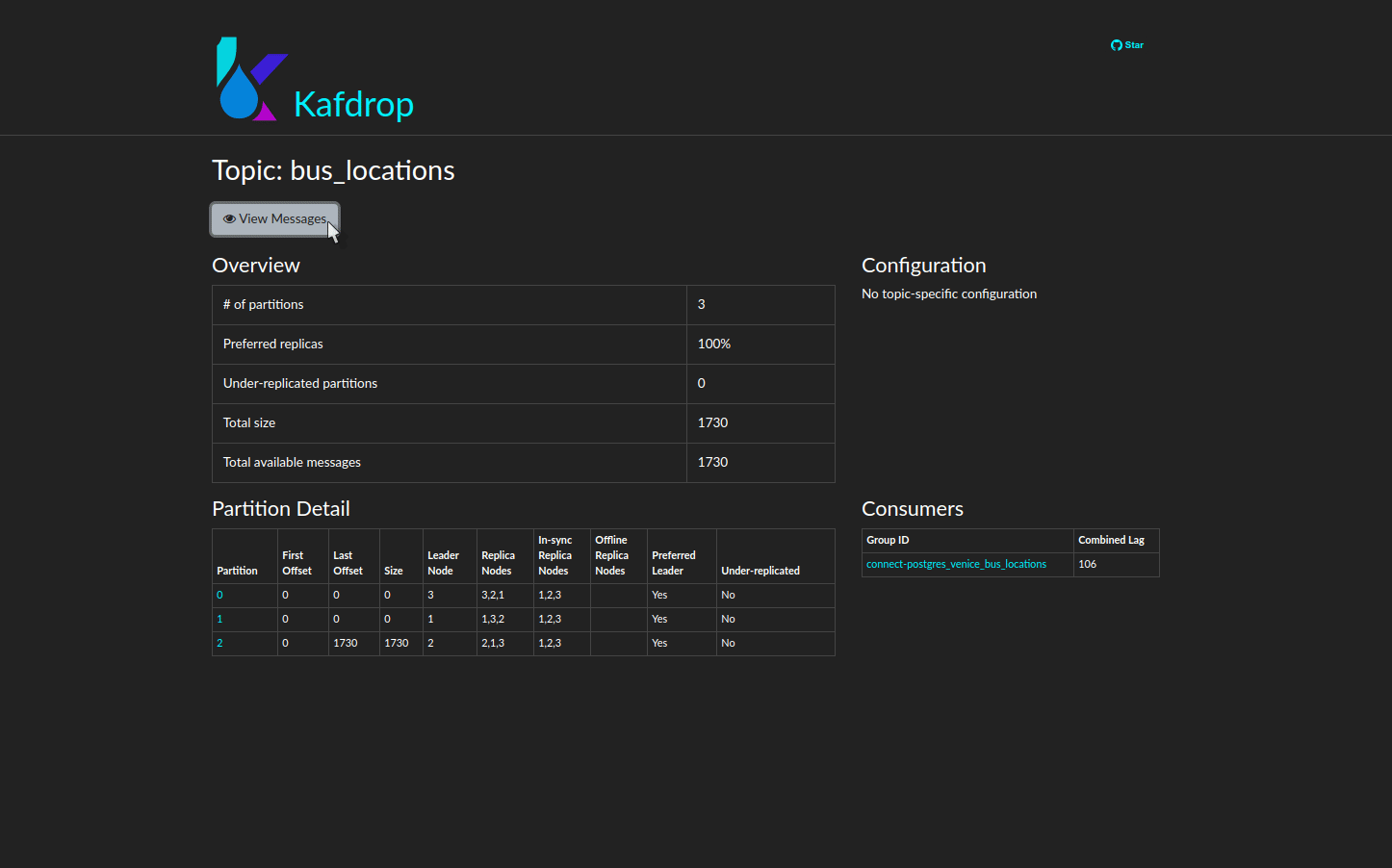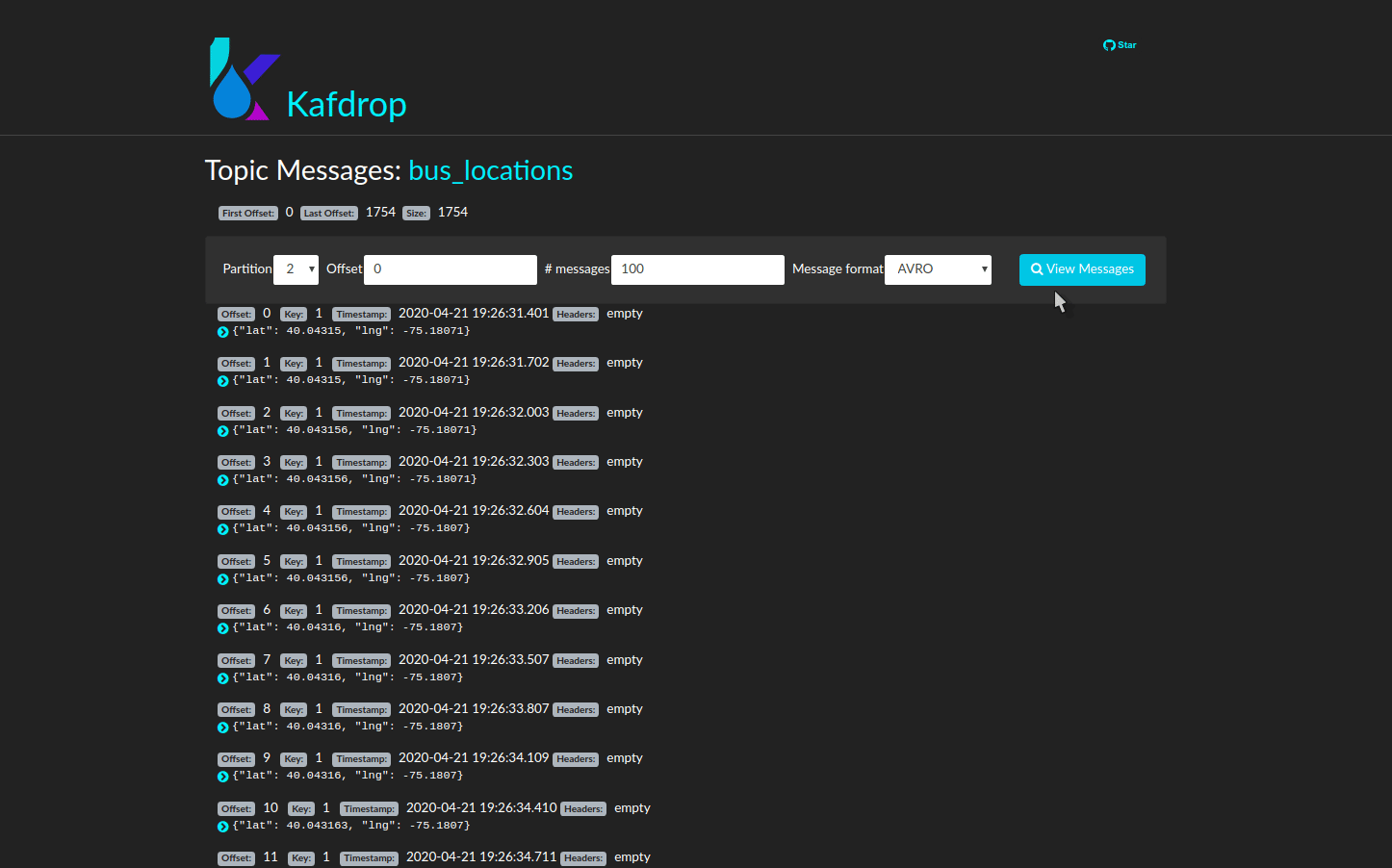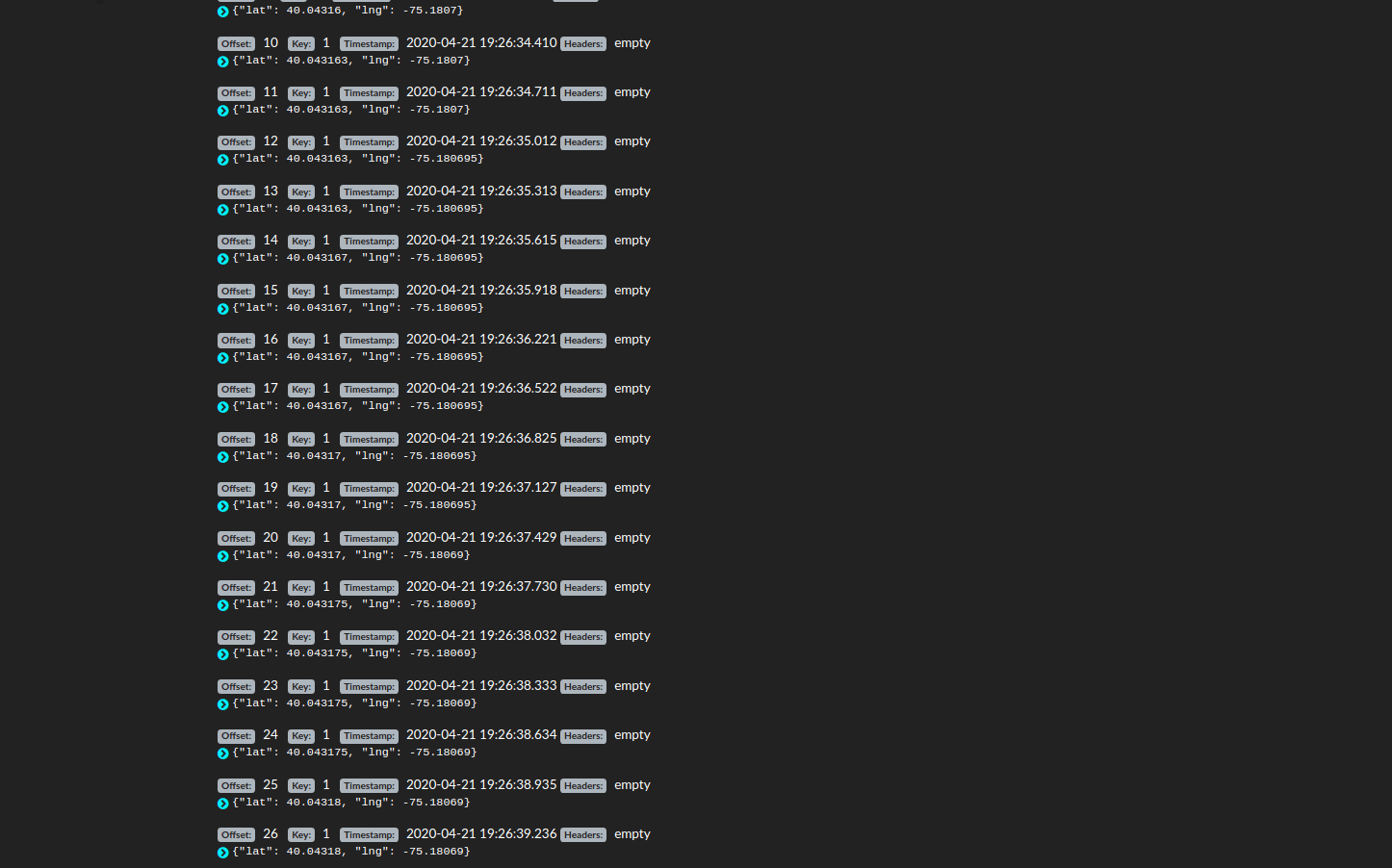
GUI
For a graphic interface for the Kafka cluster, navigate to
localhost:9000 in your web browser. Here you can view
Kafka topics and consumer groups. You can examine individual
messages to ensure they are being serialized and deserialized
correctly. You can also verify message distribution among partitions
to ensure balance.
Shut down the Venice pipeline
venice down